
-
내가 정리한 Part (5.1 람다식과 멤버 참조)
-
들어가기 용어 초 간단 정리
-
5.1.1 람다 소개: 코드 블록을 함수 인자로 넘기기
-
5.1.2 람다와 컬렉션
-
5.1.3 람다 식의 문법
-
5.1.4 현재 영역에 있는 변수에 접근
-
5.1.5 멤버 참조
-
팀원2 Part (5.2 컬렉션 함수형 API)
-
5.2.2 all, any, count, find : 컬렉션에 술어 적용
-
5.2.4 flatMap과 flatten : 중첩된 컬렉션 안의 원소 처리
-
flatMap vs flatten vs map 차이점 정리
-
팀원3 Part (5.3 지연 계산(Lazy) 컬렉션 연산)
-
즉시 실행 vs 지연 실행
-
시퀀스 연산 실행 순서
-
5.3.1 generateSequence를 이용한 무한 시퀀스 생성
-
5.3.2 디렉터리 탐색에 시퀀스 활용
-
팀원4 part (5-4. 자바 함수형 인터페이스 활용)
-
함수형 인터페이스(Fuctional Interface)?
-
5.4.1 자바 메소드에 람다를 인자로 연결
-
5.4.2 SAM 생성자: 람다를 함수형 인터페이스로 명시적으로 변경
-
팀원5 part (5.5 수신 객체 지정 람다: with와 apply)
-
5.5.1 with 함수
-
5.5.2 apply 함수
-
도서 링크 바로가기
Kotlin in Action을 공부하며 정리한 내용입니다.
저작권에 문제가 될 시, 글을 모두 내리겠습니다.
제가 공부한 내용이 더 많은 분들에게도 도움이 되었으면 좋겠습니다. 부족한 부분은 댓글을 통해서 피드백을 주신다면 언제나 반영하겠습니다. 감사합니다.
책에 대한 링크는 맨 아래에 있습니다.
https://github.com/Kotlin-Android-Study-with-SSAFY/Kotlin_In_Action_1
GitHub - Kotlin-Android-Study-with-SSAFY/Kotlin_In_Action_1: SSAFY 13기 모바일 트랙 구미 5반 "코틀린 인 액션" 스
SSAFY 13기 모바일 트랙 구미 5반 "코틀린 인 액션" 스터디(A). Contribute to Kotlin-Android-Study-with-SSAFY/Kotlin_In_Action_1 development by creating an account on GitHub.
github.com
내가 정리한 Part (5.1 람다식과 멤버 참조)
들어가기 용어 초 간단 정리
- 람다란 익명 함수(anonymous function) 의 일종으로, 함수의 이름 없이 정의할 수 있는 간결한 표현 방식이다.
- 고차함수란 다른 함수를 매개변수로 받거나 반환하는 함수를 의미한다.
- 1급 객체(First-Class Citizen)란 프로그래밍 언어에서 특정 요소(예: 변수, 함수 등)를 값처럼 취급할 수 있는 개념을 의미한다.
5.1.1 람다 소개: 코드 블록을 함수 인자로 넘기기
자바에서는 특정 이벤트 발생 시 실행할 동작을 정의하기 위해 무명 내부 클래스를 사용했지만, 이는 코드가 번잡해지는 단점이 있다. 반면, 함수형 프로그래밍에서는 함수를 값처럼 다룰 수 있어 코드가 간결해진다.
람다 식을 사용하면 클래스를 선언할 필요 없이 코드 블록을 직접 함수의 인자로 전달할 수 있다. 예를 들어, 버튼 클릭 이벤트를 처리하는 리스너를 추가할 때 자바에서는 아래처럼 작성해야 한다.
/* 자바 */
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View view) {
/* 클릭 시 수행할 동작 */
}
});무명 내부 클래스를 사용하면 코드가 복잡해지며, 여러 곳에서 반복 사용되면 가독성이 떨어진다.
코틀린에서는 람다를 활용해 더욱 간결한 코드 작성이 가능하다.
/* 코틀린 */
button.setOnClickListener { /* 클릭 시 수행할 동작 */ }이 코드도 동일한 동작을 수행하지만, 더욱 간결하고 직관적이다. 이처럼 코틀린 람다는 메소드가 하나뿐인 인터페이스(예: 클릭 리스너)를 대체할 수 있으며, 코드의 가독성과 유지보수성을 높이는 데 유용하다.
5.1.2 람다와 컬렉션
코드에서 중복을 제거하는 것은 프로그래밍 스타일을 개선하는 중요한 방법 중 하나다. 특히 컬렉션을 다룰 때 반복되는 패턴이 많기 때문에, 이를 효율적으로 처리할 수 있는 라이브러리 함수가 필요하다.
코틀린에서는 컬렉션을 쉽게 다룰 수 있는 람다 기반의 라이브러리 함수가 제공되므로, 직접 구현할 필요가 없다.
=> 많이 사용해보자.
fun findTheOldest(people: List<Person>) {
var maxAge = 0
var theOldest: Person? = null
for (person in people) {
if (person.age > maxAge) {
maxAge = person.age
theOldest = person
}
}
println(theOldest)
}위 코드는 people 리스트에서 가장 나이가 많은 사람을 찾는 코드이다. 그러나 반복문과 변수 변경이 많아 가독성이 떨어진다.
println(people.maxBy { it.age })위 코드처럼 maxBy 함수를 사용하면 한 줄로 동일한 동작을 수행할 수 있다.
{ it.age }는 Person 객체의 age 프로퍼티를 기준으로 비교하도록 한다.- it 키워드는 컬렉션의 각 원소(Person)를 가리킨다.
더더더더 간결한 코드
people.maxBy(Person::age){ it.age }대신 멤버 참조(Person::age)를 사용하면 더욱 직관적인 코드가 된다.- 이는 Person 클래스의 age 프로퍼티를 기준으로 최댓값을 찾는 기능을 수행한다.
- 결론 람다는 신이댜.
5.1.3 람다 식의 문법
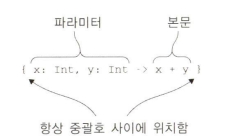
코틀린 람다는 항상 중괄호{} 로 감싸며, 괄호 없이 매개변수를 정의하고 화살표(->) 로 본문과 구분한다.
람다가 변수에 저장되면 일반 함수처럼 호출할 수 있다.
>>> { println(42) } ()
42
>>> run { println(42) }
42{ println(42) } ()→ 람다를 즉시 실행run { println(42) }→ run 함수를 사용하여 람다 실행- 괄호를 굳이 붙이지 않아도 됨.
람다는 다른 함수의 인자로 전달될 수 있다.
people.maxBy({ p: Person -> p.age })위 코드에서 { p: Person -> p.age }는 Person 타입의 인자를 받아 age 값을 반환하는 람다이다.
하지만 이 방식은 괄호와 중괄호가 많아 가독성이 떨어진다. =>
people.maxBy() { p: Person -> p.age } // 람다를 괄호 밖으로 이동
people.maxBy { p: Person -> p.age } // 유일한 인자라면 괄호 생략 가능- 람다가 유일한 인자라면 괄호를 생략하는 것이 일반적이다.
joinToString 함수는 컬렉션 원소를 문자열로 변환하는 함수이다. (3장에서 해봄)
람다를 활용하면 각 원소를 특정 방식으로 변환할 수 있다.
>>> val people = listOf(Person("이몽룡", 29), Person("성춘향", 31))
>>> val names = people.joinToString(separator = " ", transform = { p: Person -> p.name })
>>> println(names)이를 괄호 밖으로 빼면 더 간결해진다.
위 코드에서 transform 인자로 { p: Person -> p.name } 람다를 전달하여
각 Person 객체의 name만 추출하고 공백으로 연결한다.
people.joinToString(" ") { p: Person -> p.name }람다가 마지막 인자이므로 괄호 밖으로 이동할 수 있다.
람다에서 매개변수의 타입을 생략*할 수 있다.
코틀린 컴파일러가 문맥을 분석하여 자동으로 타입을 추론하기 때문이다.
people.maxBy { p -> p.age } // Person 타입을 컴파일러가 추론 가능maxBy는 Person 타입의 컬렉션에서 사용되므로, p는 Person 타입으로 자동 추론된다.
람다의 매개변수가 하나일 때는 it 키워드를 사용할 수 있다.
people.maxBy { it.age } // it을 사용하여 더 간결하게 표현 가능it은 람다의 유일한 매개변수일 때 자동으로 생성되는 이름이다.
But it의 사용은 정말 간단할 때만 사용한다.
it 키워드는 람다의 매개변수가 하나일 때 자동으로 제공되는 암시적 변수이다. 하지만 모든 경우에 it을 사용하는 것이 최선은 아니다.
// it을 써도 좋은 예시
val numbers = listOf(1, 2, 3, 4, 5)
val evenNumbers = numbers.filter { it % 2 == 0 }
println(evenNumbers) // 결과: [2, 4]- 가독성을 크게 해치지 않는다.
// it을 쓰면 나쁜 경우
val people = listOf(Person("Alice", 29), Person("Bob", 31))
val adults = people.filter { it.age > 18 && it.name.startsWith("A") }
// 개선 코드
val adults = people.filter { person -> person.age > 18 && person.name.startsWith("A") }- it이 Person 객체를 가리킨다는 것이 명확하지 않다.
- 나중에 코드가 복잡해지면 어떤 속성을 참조하는지 파악하기 어려울 수 있다.
람다를 변수에 저장할 때는 타입 명시 필요
>>> val getAge = { p: Person -> p.age }
>>> people.maxBy(getAge)- 람다를 변수에 저장할 때는 컴파일러가 타입을 추론할 문맥이 없으므로 타입을 명시해야한다.
람다는 여러 줄로 구성될 수도 있으며, 마지막 표현식의 결과가 반환된다.
>>> val sum = { x: Int, y: Int ->
println("Computing the sum of $x and $y...")
x + y
}
>>> println(sum(1, 2))
Computing the sum of 1 and 2...
3
5.1.4 현재 영역에 있는 변수에 접근
코틀린의 람다는 외부 함수의 변수를 포획(capture)하여 사용할 수 있으며, 그 값을 변경할 수도 있다.
이는 클로저(closure) 라고 불리며, 함수 실행이 끝난 후에도 포획한 변수가 유지되는 특징을 가진다.
람다는 함수 내부에서 선언된 변수뿐만 아니라, 함수의 매개변수에도 접근 가능하다.
fun printMessagesWithPrefix(messages: Collection<String>, prefix: String) {
messages.forEach {
println("$prefix $it")
}
}- prefix는 함수 매개변수이지만, forEach 람다 내부에서 자유롭게 사용 가능
- 이는 람다가 외부 변수(prefix)를 포획하여 접근할 수 있기 때문
자바와 다르게 코틀린에서는 람다 내부에서 외부 변수 값을 변경할 수도 있다.
fun printProblemCounts(responses: Collection<String>) {
var clientErrors = 0
var serverErrors = 0
responses.forEach {
if (it.startsWith("4")) {
clientErrors++
} else if (it.startsWith("5")) {
serverErrors++
}
}
println("$clientErrors client errors, $serverErrors server errors")
}
>>> val responses = listOf("200 OK", "418 I'm a teapot", "500 Internal Server Error")
>>> printProblemCounts(responses)
// 결과: 1 client errors, 1 server errors- clientErrors와 serverErrors는 람다 내부에서 변경되지만, 외부 변수이므로 값이 유지됨
- 람다가 이 변수를 포획(Capture) 했기 때문에, 함수 실행 후에도 값이 변경된 상태로 유지
람다는 함수 실행이 끝나도 포획한 변수를 계속 유지할 수 있다.
즉, 람다가 종료된 후에도 변수 값을 읽고 수정할 수 있는 구조를 클로저(Closure) 라고 한다.
fun main() {
var counter = 0 // 람다가 포획할 변수
val increment: () -> Unit = { counter++ } // counter 변수 포획
increment()
increment()
println(counter) // 결과: 2 (counter 값이 유지됨)
}increment()실행 시 counter 값이 증가하며, 람다 실행이 끝나도 변수 값이 유지됨
포획된 변수는 람다가 유지되는 한 계속 사용 가능하다.
fun createCounter(): () -> Int {
var count = 0 // 포획할 변수
return { ++count } // 람다가 count를 포획
}
fun main() {
val counter1 = createCounter()
val counter2 = createCounter()
println(counter1()) // 결과: 1
println(counter1()) // 결과: 2
println(counter2()) // 결과: 1 (새로운 클로저)
}- counter1()과 counter2()는 서로 다른 람다 인스턴스를 사용하므로 독립적인 count 값을 유지
람다 내부에서 외부 리스트에 값을 추가하는 경우, 리스트 자체가 포획되어 유지된다.
fun main() {
val clientErrors = mutableListOf<Int>()
val serverErrors = mutableListOf<Int>()
val processError: (Int) -> Unit = { code ->
if (code in 400..499) clientErrors.add(code) // clientErrors 포획
else if (code in 500..599) serverErrors.add(code) // serverErrors 포획
}
processError(404)
processError(500)
processError(403)
println("Client Errors: $clientErrors") // 결과: [404, 403]
println("Server Errors: $serverErrors") // 결과: [500]
}- 외부 리스트(clientErrors, serverErrors)가 람다에 의해 포획되었기 때문에 함수 실행 후에도 값이 유지됨
- 람다를 비동기적으로 실행할 경우, 함수 실행이 끝난 후에도 로컬 변수가 남아 예상과 다른 결과를 초래할 수 있다.
fun tryToCountButtonClicks(button: Button): Int {
var clicks = 0
button.onClick { clicks++ }
return clicks
}
문제점
- onClick 핸들러는 tryToCountButtonClicks()가 끝난 후 실행되므로, clicks++이 실행되어도 함수가 반환한 값에는 반영되지 않는다.
- 항상 0을 반환하게 된다
해결 방법
- 클래스의 프로퍼티나 전역 변수로 clicks 값을 관리하면 해결 가능
class ClickCounter { var clicks = 0 fun registerClickHandler(button: Button) { button.onClick { clicks++ } } }- 이렇게 하면 clicks 변수가 함수 실행과 독립적으로 유지되어 정상 동작함
5.1.5 멤버 참조
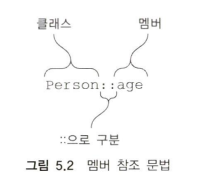
람다를 사용하면 코드 블록을 함수의 인자로 전달할 수 있다. 하지만 이미 선언된 함수를 사용할 경우, 람다를 만들지 않고 직접 전달하는 방법이 있을까?
코틀린에서는 이중 콜론(::)을 사용하여 함수나 프로퍼티를 값처럼 다룰 수 있다.
이것을 멤버 참조(Member Reference) 라고 한다.
val getAge = Person::agePerson::age는 Person 객체의 age 프로퍼티를 참조하는 멤버 참조이다.- 이는
{ p -> p.age }람다와 같은 역할을 한다.
멤버 참조는 람다와 같은 역할을 수행할 수 있으며, 더 간결한 표현이 가능하다.
people.maxBy { p -> p.age } // 람다 사용
people.maxBy { it.age } // 람다에서 'it' 사용
people.maxBy(Person::age) // 멤버 참조 사용 (더 간결함)- Person::age는 { p -> p.age } 람다와 동일한 기능을 수행
- 더 짧고 가독성이 좋은 멤버 참조를 활용하면 코드가 간결해진다.
클래스 멤버뿐만 아니라, 최상위에 선언된 함수도 멤버 참조로 사용할 수 있다.
fun salute() = println("Salute!")
>>> run(::salute)
Salute!- ::salute를 run 함수에 전달하여 실행
- run은 전달받은 함수(람다)를 실행하는 역할을 한다.
람다가 단순히 다른 함수에 작업을 위임하는 경우, 람다를 정의할 필요 없이 멤버 참조를 직접 사용할 수 있다.
val action = { person: Person, message: String -> sendEmail(person, message) }
val nextAction = ::sendEmail // 멤버 참조 사용- { person, message -> sendEmail(person, message) } 람다는 불필요한 중복이 발생
- ::sendEmail로 더 간결하게 표현 가능
생성자를 참조할 수도 있다. 생성자를 변수에 저장하거나, 지연 초기화할 때 유용하다.
data class Person(val name: String, val age: Int)
>>> val createPerson = ::Person
>>> val p = createPerson("Alice", 29)
>>> println(p)
Person(name=Alice, age=29)- ::Person은 Person 클래스의 생성자를 참조
- createPerson("Alice", 29)를 호출하면 Person 객체가 생성됨
확장 함수도 멤버 참조를 통해 참조할 수 있다.
fun Person.isAdult() = age >= 21
val predicate = Person::isAdult- Person::isAdult는 확장 함수를 참조하는 방식
- predicate(Alice)처럼 사용 가능
팀원2 Part (5.2 컬렉션 함수형 API)
- filter와 map은 컬렉션을 활용할 때 기반이 되는 함수 → 대부분의 컬렉션 연산을 이 두 함수를 통해 표현 가능
고차함수(HOF, High Order Function) : 함수형 프로그래밍에서 람다나 다른 함수를 인자로 받거나 함수를 반환하는 함수
- 장점 : 기본 함수를 조합해서 새로운 연산을 정의 or 다른 고차 함수를 통해 조합된 함수를 또 조합해서 더 복잡한 연산을 쉽게 정의 가능
- 컴비네이터 패턴(combinator pattern) : 고차함수와 단순한 함수를 이리저리 조합해서 코드를 작성하는 기법
- 컴비네이터(combinator) : 컴비네이터 패턴에서 복잡한 연산을 만들기 위해 값이나 함수를 조합할 때 사용하는 고차 함수
- filter 함수 : 컬렉션을 이터레이션하면서 주어진 람다에 각 원소를 넘겨서 람다가 true를 반환하는 원소만 모음
>>> val list = listOf(1, 2, 3, 4)
>>> println(list.filter {it % 2 == 0}) <-짝수만 남음
**[2, 4]**- filter 함수는 컬렉션에서 원치 않는 원소를 제거한다. 하지만 filter는 원소를 변환 불가능하다. 원소를 변환하려면 map 함수를 사용
- map 함수 : 주어진 람다를 컬렉션의 각 원소에 적용한 결과를 모아서 새 컬렉션을 만듦
>>> val list = listOf(1, 2, 3, 4)
>>> println(list.map { it * it })
[1, 4, 9, 16]
- 사람의 리스트가 아니라 이름의 리스트를 출력하고 싶다면 map으로 사람의 리스트를 이름의 리스트로 변환
>>> val people = listOf (Person("Alice", 29), Person("Bob", 31))
>>> println (people.map { it.name })
[Alice, Bob]people.map(Person::name)>>> (people.filter({it.age > 30 })).map(Person::name) <- 괄호를 명확히 사용
>>> people.filter{ it.age > 30 }.map(Person::name) <- 구문을 훨씬 간결하게 표현 가능
[Bob]
가장 나이 많은 사람의 이름을 알고 싶을 경우
<일반적인 방법>
- 목록에 있는 사람들의 나이의 최대값 구하기
- 나이가 그 최댓값과 같은 모든 사람 반환
people.filter { it.age == people.maxBy (Person::age)!!.age }→ 단점 : 목록에서 최댓값을 구하는 작업을 계속 반복(100명일 경우 100번 반복)
- 개선 방법 : 최댓값을 한 번만 계산
val maxAge = people.maxBy(Person::age) !!.age
people.filter { it.age == maxAge }꼭 필요하지 않은 경우 굳이 계산을 반복하지 말라! 인자로 받는 함수에 람다를 넘기면 겉으로 볼 때 단순해 보이는 식이 내부 로직의 복잡도로 인해 실제로는 엄청나게 불합리한 계산식이 될 때가 있음
- 필터와 변환 함수를 맵(키와 값을 연관시켜주는 데이터 구조)에 적용 가능
>>> val numbers = mapOf(0 to "zero", 1 to "one")
>>> println(numbers.mapValues { it.value.toUpperCase() })
{0=ZERO, 1=ONE}- 맵의 경우 키와 값을 처리하는 함수 따로 존재
- 키를 걸러 내거나 변환 : filterKeys, mapKeys
- 값을 걸러 내거나 변환 : filterValues, mapValues
5.2.2 all, any, count, find : 컬렉션에 술어 적용
- all, any : 컬렉션의 모든 원소가 어떤 조건을 만족하는지 판단(또는 컬렉션 안에 어떤 조건을 만족하는 원소가 있는지 판단) → true / false
- count : 조건을 만족하는 원소의 개수를 반환
- find : 조건을 만족하는 첫 번째 원소 반환
val canBeInClub27 = { p: Person -> p.age <= 27 }
- 모든 원소가 이 술어를 만족하는 지 궁금할 경우
>>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
>>> println(people.all(canBeInClub27))
false- 술어를 만족하는 원소가 하나라도 있는 지 궁금할 경우
>>> println(people.any(canBeInClub27))
true
드 모르강의 법칙(De Morgan’s Theorem)
- 어떤 조건에 대해 !all을 수행한 결과가 그 조건의 부정에 대해 any를 수행한 결과는 같음
- 어떤 조건에 대해 !any를 수행한 결과와 그 조건의 부정에 대해 all을 수행한 결과도 같음
→ 가독성을 높이려면 any와 all 앞에 !를 붙이지 않는 편이 나음
>>> val list = listOf(1, 2, 3)
>>> println(!list.all { it == 3 })
true>>> val list = listOf(1, 2, 3)
>>> println(list.any { it != 3 })
true- 술어를 만족하는 원소의 개수 구하려는 경우
>>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
>>> println(people.count(canBeInClub27))
1
함수를 적재적소에 사용하라 : count와 size
- count가 있다는 사실을 잊고, 컬렉션을 필터링한 결과의 크기를 가져오는 경우가 있음
>>> println (people.filter(canBeInClub27).size)
1- 하지만 이렇게 처리하면 조건을 만족하는 모든 원소가 들어가는 중간 컬렉션이 생긴다. 반면 count는 조건을 만족하는 원소의 개수만을 추적함. 조건을 만족하는 원소를 따로 저장하지 않는다. 따라서 count가 훨씬 더 효율적임
- 술어를 만족하는 원소를 하나 찾고 싶은 경우
>>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
>>> println (people.find(canBeInClub27))
Person (name=Alice, age=27)- 이 식은 조건을 만족하는 원소가 하나라도 있는 경우 → 가장 먼저 조건을 만족한다고 확인된 원소를 반환
- 만족하는 원소가 없는 경우 → null 반환
- groupby : 특성을 파라미터로 전달하면 컬렉션을 자동으로 구분해주는 함수
>>> val people = listOf (Person("Alice", 31),
... Person("Bob", 29), Person("Carol", 31))
>>> println (people.groupBy { it.age })
{29=[Person (name=Bob, age=29)],
31=[Person (name=Alice, age=31), Person (name=Carol, age=31)]}- 연산의 결과 → 컬렉션의 원소를 구분하는 특성이 키이고, 키 값에 따른 각 그룹이 값인 맵
- groupBy의 결과 타입 → Map<Int, List<Person>>
>>> val list = listOf("a", "ab", "b")
>>> println(list.groupBy(String::first))
{a=[a, ab], b=[b) }- first는 String의 멤버가 아닌 확장 함수이지만 여전히 멤버 참조를 사용해 first에 접근 가능
5.2.4 flatMap과 flatten : 중첩된 컬렉션 안의 원소 처리
- Book으로 표현한 책에 대한 정보를 저장하는 도서관이 있다고 가정
class Book(val title: String, val authors: List<String>)- 책마다 저자가 한 명 또는 여러 명 존재
books.flatMap { it.authors }.toSet()- flatMap 함수로 먼저 인자로 주어진 람다를 컬렉션의 모든 객체에 적용하고(또는 매핑하기 map) 람다를 적용한 결과 → 여러 리스트를 한 리스트로 모음(또는 펼치기 flatten)
>>> val strings = listOf("abc", "def")
>>> println(strings.flatMap { it.toList() })
[a, b, c, d, e, f]- toList 함수 : 문자열에 적용하면 그 문자열에 속한 모든 문자로 이뤄진 리스트가 만들어짐
- flatMap 함수 : 다음 단계로 리스트의 리스트에 들어있던 모든 원소로 이뤄진 단일 리스트 반환
>>> val books = listOf (Book("Thursday Next", listOf ("Jasper Fforde")),
Book ("Mort", listOf("Terry Pratchett")),
Book ("Good Omens", listOf("Terry Pratchett",
"Neil Gaiman")))
>>> println (books.flatMap { it.authors }.toSet())
[Jasper Fforde, Terry Pratchett, Neil Gaiman]- 상단 코드 설명
- book.authors 프로퍼티는 작가를 모아둔 컬렉션
- flatMap 함수는 모든 책의 작가를 평평한(문자열로만 이뤄진) 리스트 하나로 모음
- toSet 함수는 flatMap의 결과 리스트에서 중복을 없애고 집합을 만듦
- flatMap의 용도 : 리스트의 리스트가 있는데 모든 중첩된 리스트의 원소를 한 리스트로 모아야 할 경우
- flatten 함수 : 특별히 변환해야 할 내용이 없다면 리스트의 리스트를 평평하게 펼치기만 하면 되는 경우 → 사용법 : listOfLists.flatten()
flatMap vs flatten vs map 차이점 정리
| 함수 | 기능 | 변환 가능? | 예제 입력 | 결과 |
| flatMap | 변환 후 평탄화 | 가능 | listOf(1, 2, 3),flaMap { listOf(it, it * 10) } | [1, 10, 2, 20, 3, 30] |
| flatten | 평탄화만 수행 | 불가능 | listOf(listOf(1, 2), listOf(3, 4)).flatten() | [1, 2, 3, 4] |
| map | 변환만 수행(평탄화 없음) | 가능 | listOf("abc", "def").map { it.toList() } | [[a, b, c], [d, e, f]] |
팀원3 Part (5.3 지연 계산(Lazy) 컬렉션 연산)
즉시 실행 vs 지연 실행
기본적으로 map이나 filter 같은 컬렉션 연산은 즉시 실행 방식으로 동작한다. 즉, 각 연산이 수행될 때마다 새로운 리스트를 생성하여 결과를 저장한다.
val people = listOf(Person("Alice", 29), Person("Bob", 31), Person("Charles", 31), Person("Dan", 21))
val names = people.map { it.name }.filter { it.startsWith("A") }
println(names) // [Alice]위 코드의 문제점:
- map { it.name }을 실행하면 새로운 리스트가 생성됨.
- filter { it.startsWith("A") }을 실행할 때 또 새로운 리스트가 생성됨.
- 즉, 중간 결과를 저장하는 불필요한 리스트가 계속 만들어짐 → 비효율적!
시퀀스(Sequence) 를 사용하면 이러한 중간 컬렉션을 생성하지 않고도 연산을 연쇄적으로 적용할 수 있다.
val namesLazy = people.asSequence()
.map { it.name }
.filter { it.startsWith("A") }
.toList()
println(namesLazy) // [Alice]어떤 차이가 있을까?
- asSequence()를 사용하면 시퀀스 변환 후 지연 계산 방식으로 동작한다.
- 중간 연산(map, filter)은 실제로 데이터를 처리하지 않고, 최종 연산(toList())이 호출될 때 연산이 수행됨.
- 불필요한 중간 리스트가 만들어지지 않으므로 메모리 사용량이 줄어들고 성능이 개선됨
시퀀스 연산 실행 순서
아래 코드를 실행하면 연산이 수행되는 순서를 확인할 수 있다.
listOf(1, 2, 3, 4).asSequence()
.map { print("map($it) "); it * it }
.filter { print("filter($it) "); it % 2 == 0 }
.toList()출력 결과
map(1) filter(1) map(2) filter(4) map(3) filter(9) map(4) filter(16)
| 방식 | 즉시 실행 방식 ( List ) | 지연 실행 방식 (Sequence ) |
| 연산 방식 | map 실행 후 모든 요소 변환 -> filter 실행 | map 실행 후 즉시 filter 적용 |
| 중간 컬렉션 | map 실행 후 새로운 리스트 실행 | 중간 리스트 없이 연산 수행 |
| 연산 순서 | 모든 요소 변환 후 필터링 | 한 요소씩 변환 후 필터링 |
| 효율성 | 데이터가 많아질수록 불필요한 연산 증가 | 불필요한 연산이 최소화 됨 |
즉시 실행 방식 문제점
- map이 모든 요소에 대해 변환을 수행한 후 새로운 리스트 생성.
- filter가 새로운 리스트를 다시 필터링하면서 추가적인 연산 수행.
- 중간 결과를 저장하는 리스트가 계속 만들어져 메모리 낭비 발생
지연 실행 방식의 장점
- map과 filter가 각 요소별로 차례로 실행됨.
- 중간 리스트를 만들지 않고 바로 연산을 수행하여 메모리 절약 & 성능 향상
5.3.1 generateSequence를 이용한 무한 시퀀스 생성
일반 리스트(List<Int>)는 고정된 크기를 갖지만, 시퀀스는 필요할 때만 값을 생성하고 사용할 수 있음.
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo100 = naturalNumbers.takeWhile { it < 100 }
println(numbersTo100.sum()) // 5050- generateSequence(0) { it + 1 }
- 0부터 시작해서 1씩 증가하는 무한 시퀀스를 생성.
- takeWhile { it < 100 }
- 100보다 작은 숫자까지만 가져옴.
- sum()
- 최종 연산이 호출될 때까지 연산이 수행되지 않음.
일반 리스트를 사용하면 100개의 요소를 미리 생성해야 하지만, 시퀀스를 사용하면 필요한 만큼만 계산하여 성능이 더 우수하다.
5.3.2 디렉터리 탐색에 시퀀스 활용
파일 시스템을 탐색할 때, 특정 파일이 숨김 폴더 안에 있는지 확인하고 싶을 수 있다.
이럴 때 시퀀스를 사용하면 부모 폴더를 하나씩 탐색하며 조건을 만족하는지 검사할 수 있다.
fun File.isInsideHiddenDirectory(): Boolean =
generateSequence(this) { it.parentFile }.any { it.isHidden }
val file = File("/Users/svtk/.HiddenDir/a.txt")
println(file.isInsideHiddenDirectory()) // true- generateSequence(this) { it.parentFile }
- 현재 파일(this)에서 부모 디렉터리를 따라 올라가는 시퀀스를 생성.
- .any { it.isHidden }
- 부모 폴더 중 하나라도 숨김 폴더라면 true 반환.
- 숨김 폴더를 찾으면 즉시 탐색 종료 → 불필요한 연산 방지
기존 방식처럼 모든 부모 디렉터리를 리스트에 저장할 필요 없이, 조건을 만족하면 바로 탐색을 종료할 수 있다.
팀원4 part (5-4. 자바 함수형 인터페이스 활용)
우리가 다뤄야 하는 API 중 상당수는 코틀린이 아니라 자바로 작성된 API일 가능성이 높다. 다행인 점은 코틀린 람다를 자바 API에 사용해도 아무 문제가 없다는 사실이다.
button.setOnCllickListener(/* 클릭 시 실행할 동작 */);- 버튼(Button)을 클릭했을 때 실행할 동작을 정해주기 위해 setOnClickListener 메서드를 사용
- setOnClickListener 메서드의 인자(매개변수)로 OnClickListener 인터페이스 타입의 객체를 넘겨줘야 한다.
Button 클래스
public class Button{
public void setOnClickListener(OnClickListener 1){...}
}
onClickListener 인터페이스
public interface OnClickListener{
void onClick(View v);
}- OnClickListener는 onClick(View v)라는 메소드만 선언된 인터페이스
- 버튼을 클릭했을 때 실행할 동작을 정의하려면 OnClickListener를 구현한 객체를 만들어야 한다!
자바 8 이전의 방식(익명 클래스 사용)
button.setOnClickListener(new OnClickListener(){
@Override
public void onClick(View v){
//버튼 클릭 시 실행할 코드
System.out.println("버튼이 클릭됨!");
}
});- 자바 8 이전에는 인터페이스를 직접 구현한 익명 클래스를 만들어서 버튼 클릭 이벤트를 처리했다.
- new OnClickListener() → OnClickListener 인터페이스를 구현하는 익명 클래스를 만들었어
- onClick(View v) → 이 메서드를 오버라이드해서 버튼을 클릭했을 대 실행할 동작을 정의한 거야.
코틀린에서 람다를 사용
button.setOnClickListener { view -> ... }- 코틀린에서는 무명 클래스 인스턴스 대신 람다를 넘길 수 있다.
- OnClickListener를 구현하기 위해 사용한 람다에는 view라는 파라미터가 있다.
- view의 타입은 View, 이는 onClick 메소드의 인자 타입과 같다.
람다의 파라미터는 메소드의 파라미터와 대응한다.
public interface OnClickListener {
void onClick(View v); -> { view -> ... }
}
함수형 인터페이스(Fuctional Interface)?
“단 하나의 추상 메서드만 가지는 인터페이스”를 뜻하고 SAM(Single Abstract Method) 인터페이스라고도 부른다.
- 자바에서 많이 쓰이는 대표적인 함수형 인터페이스들
- Runnable → run() 메서드 한 개만 있음.
- Callable<T> → call() 메서드 한 개만 있음.
- ActionListener → actionPerformed(ActionEvent e) 메서드 한 개만 있음.
// Runnable 인터페이스 (자바)
Runnable r = () -> System.out.println("쓰레드 실행됨!");
new Thread(r).start();// Runnable을 코틀린에서 람다로 사용
Thread { println("쓰레드 실행됨!") }.start()
자바 8 이후 람다 표현식으로 대체 가능
button.setOnClickListener(v -> {
System.out.println("버튼이 클릭됨!");
});- 자바 8 이후 람다 표현식으로 대체 가능
- OnClickListener가 단일 추상 메서드만 가진 인터페이스이므로, 람다( () → {} )로 변환 가능
- v -> { System.out.println("버튼이 클릭됨!"); } → onClick(View v)의 구현 내용을 람다로 직접 전달
코틀린에서 더 간결하게 사용 가능
button.setOnClickListener { view ->
println("버튼이 클릭됨!")
}- 코틀린은 자바의 함수형 인터페이스를 인자로 받는 메서드를 호출할 때 람다를 사용할 수 있도록 함
- 즉, setOnClickListener를 람다만으로 표현할 수 있게 해줌.
- { view -> println("버튼이 클릭됨!") } → onClick(View v)를 자동으로 람다로 변환해서 사용 가능!
“코틀린에는 함수 타입이 존재하며, 함수형 인터페이스 대신 함수 타입을 사용해야 한다"
- 자바와 코틀린의 함수 처리 방식이 다르다.
- 코틀린에는 함수 타입(Function Type) 이 존재하기 때문에, 함수형 인터페이스를 사용할 필요가 없다.
- 코틀린은 함수를 값처럼 다룰 수 있음 → 함수 타입(Function Type) 사용 가능
- 그래서 자바처럼 함수형 인터페이스를 만들 필요가 없다!
- 람다를 함수의 인자로 직접 전달할 수 있다.
- 자바에서는 왜 함수형 인터페이스가 필요할까?
- 자바에는 "함수 자체를 전달하는 기능" 이 없어.
- 그래서 람다 표현식을 사용하려면 반드시 함수형 인터페이스가 필요해!
자바에서 함수형 인터페이스 사용 예제
// 함수형 인터페이스 정의 (SAM 인터페이스)
interface MyFunction {
void run();
}
public class Main {
public static void main(String[] args) {
MyFunction f = () -> System.out.println("Hello, World!");
f.run(); // 출력: Hello, World!
}
}- 자바에서는 람다를 사용하려면 반드시 함수형 인터페이스(SAM)를 만들어야 함.
- MyFunction 인터페이스 없이 ()->{} 를 사용할 수 없음!
코틀린에서는 함수 타입이 존재한다!
- 코틀린은 "함수 자체를 값으로 사용할 수 있는 기능"이 있음!
- 즉, 코틀린에서는 함수형 인터페이스 없이도 람다를 직접 함수의 인자로 전달 가능!
코틀린에서 함수 타입 사용 예제
// 함수 타입을 매개변수로 받는 함수
fun execute(action: () -> Unit) {
action() // 전달받은 함수를 실행
}
fun main() {
execute { println("Hello, World!") }
}- () -> Unit → 함수를 인자로 받는 함수 타입 선언
- execute { println("Hello, World!") } → 함수형 인터페이스 없이 람다 전달 가능!
코틀린은 자바 함수형 인터페이스를 자동 변환해주지 않는다
자바에서는 함수형 인터페이스가 필수적이지만, 코틀린은 함수 타입을 직접 사용할 수 있기 때문에 자동 변환을 제공하지 않음.
예제: 자바 인터페이스를 코틀린에서 사용하면?
@FunctionalInterface
interface ClickListener {
void onClick();
}
public class Button {
public void setOnClickListener(ClickListener listener) {
listener.onClick();
}
}val button = Button()
// 자바 함수형 인터페이스에는 람다 사용 가능 (SAM 변환 지원)
button.setOnClickListener { println("버튼 클릭!") }- 코틀린에서는 자바의 함수형 인터페이스(SAM)를 자동으로 람다로 변환해줌
- 하지만, 코틀린에서 정의한 함수 타입은 자바의 함수형 인터페이스로 자동 변환되지 않는다!
5.4.1 자바 메소드에 람다를 인자로 연결
함수형 인터페이스를 인자로 원하는 자바 메소드에 코틀린 람다를 전달할 수 있다. 코틀린에서는 자바의 함수형 인터페이스(SAM 인터페이스)를 사용하는 메소드에 람다를 직접 전달할 수 있다. 이 과정에서 컴파일러가 자동으로 무명 클래스를 생성하고 인스턴스를 만들어준다.
자바에서 함수형 인터페이스를 인자로 받는 메서드
자바에서는 람다 표현식을 직접 사용할 수 없기 때문에 반드시 함수형 인터페이스(SAM)을 구현한 객체를 인자로 전달해야 한다.
자바에서 Runnable을 인자로 받는 메서드
void postponeComputation(int delay, Runnable computation);- Runnable은 SAM 인터페이스 (단 하나의 추상 메서드만 있음)
- computation 매개변수는 Runnable 타입이므로, Runnable을 구현한 객체를 넘겨야 함.
자바에서 Runnable을 명시적으로 넘기는 방식
postponeComputation(1000, new Runnable() {
@Override
public void run() {
System.out.println(42);
}
});- 자바에서는 보통 익명 클래스를 사용해서 Runnable을 넘겨야 해.
- new Runnable() { ... } → 익명 클래스로 Runnable을 구현
- run() 메서드 내부에서 실제로 실행될 코드(42 출력)를 작성
코틀린에서 람다로 변환하기
postponeComputation(1000) { println(42) }- 코틀린에서는 자바의 함수형 인터페이스를 직접 람다로 전달 가능!
- { println(42) } → 람다를 바로 인자로 전달!
- Runnable이 필요한 곳에 컴파일러가 자동으로 Runnable을 구현한 객체로 변환해줌.
- 자동으로 Runnable 인스턴스(Runnable을 구현한 무명 클래스의 인스턴스)로 변환해줌
코틀린에서 무명 객체를 명시적으로 사용할 수 있다.
postponeComputation(1000, object : Runnable {
override fun run() {
println(42)
}
})- 코틀린에서도 익명 객체를 직접 만들어서 사용할 수 있어.
- object : Runnable { ... } → 명시적으로 무명 객체 생성
- 자바에서 익명 클래스를 사용하는 것과 같은 방식이지만, 코틀린에서는 필요하지 않다!
- 람다는 컴파일러가 자동 변환하여 재사용할 수 있다. (인스턴스 단 하나만 만들어짐)
- 즉, 람다에 대응하는 무명 객체를 메소드를 호출할 때마다 반복 사용한다.
- 무명 객체는 메서드를 호출할 때마다 새로운 인스턴스가 생성된다.
차이점 예제
val runnable = Runnable { println(42) } // 단 하나의 인스턴스만 존재
fun handleComputation() {
postponeComputation(1000, runnable) // 같은 객체를 계속 사용
}- Runnable 객체를 변수에 저장하면 프로그램 전체에서 같은 인스턴스를 사용!
반면, 람다가 주변 변수를 포획하면 매번 새로운 인스턴스를 생성해!
fun handleComputation(id: String) { //람다 안에서 "id" 변수를 포획한다.
postponeComputation(1000) { println(id) } // 호출할 때마다 새로운 객체 생성
}- 변수를 포획한다?
- 코틀린에서는 람다 내부에서 외부 변수(주변 변수)를 사용할 수 있다. 이때 람다는 외부 변수를 직접 참조하는 것이 아니라, 그 변수를 포함하는 새로운 객체를 생성하는데, 이를 "변수를 포획(Capture)한다"라고 한다!
- { println(id) } → 람다가 id 변수를 포획
- 호출할 때마다 새로운 Runnable 인스턴스가 만들어짐!
람다를 무명 클래스(Anonymous Class)로 변환하는 과정과 최적화 방법을 다루고 있어.
람다는 무명 클래스로 변환된다 → 코틀린에서 람다는 사실상 익명 함수야.
즉, 컴파일될 때 무명 클래스로 변환되어 객체가 생성된다.
fun handleComputation(id: String) {
postponeComputation(1000) { println(id) }
}- { println(id) } → 람다 사용
- 컴파일러는 이 람다를 Runnable을 구현한 익명 클래스로 변환해.
람다를 무명 클래스로 변환하는 방식
- 컴파일러는 람다를 포함하는 무명 클래스를 생성하고,
- 해당 클래스의 인스턴스를 만들어서 메서드에 넘긴다.
변환된 코드 (컴파일 후 예상되는 코드)
class HandleComputationS1(val id: String) : Runnable {
override fun run() {
println(id)
}
}
fun handleComputation(id: String) {
postponeComputation(1000, HandleComputationS1(id))
}- HandleComputationS1 → Runnable을 구현한 새로운 클래스가 자동 생성됨.
- 람다 내부에서 외부 변수(id)를 사용하면 필드로 저장해야 함.
- 따라서 호출할 때마다 새로운 객체가 생성됨!
람다가 외부 변수를 포획하면?
- 람다가 외부 변수를 사용(포획) 하면,
- 컴파일러는 해당 변수를 저장할 필드를 가진 새로운 무명 클래스를 생성해.
람다가 외부 변수를 포획하는 경우
fun handleComputation(id: String) {
postponeComputation(1000) { println(id) } // id를 포획
}- id 변수를 사용했기 때문에 id를 저장할 필드가 있는 클래스가 생성됨.
- 그리고 handleComputation("Hello") 를 호출할 때마다 새로운 객체가 생성됨.
최적화: 코틀린의 inline 함수
- 코틀린에서는 inline 키워드를 사용하면 무명 클래스를 만들지 않고 최적화할 수 있어!
- 즉, 무명 클래스를 생성하는 대신, 함수 자체를 복사해서 사용함.
inline 최적화 적용
inline fun handleComputation(id: String) {
postponeComputation(1000) { println(id) } // id를 포획하지만 무명 클래스 생성 없음
}- inline 키워드를 사용하면 컴파일러가 람다 자체를 코드에 삽입!
- 따라서 무명 클래스가 생성되지 않음 → 성능 최적화 가능!
Inline의 장점
- 무명 클래스 인스턴스를 생성하지 않음 → 메모리 절약
- 메서드 호출 없이 코드 자체를 삽입 → 함수 호출 오버헤드 감소
- 반복적으로 호출되는 경우 성능 개선 가능!
정리
- 코틀린 람다는 기본적으로 무명 클래스로 변환됨.
- 람다가 외부 변수를 포획하면, 변수를 저장할 필드가 있는 새로운 객체가 생성됨.
- handleComputation("Hello")를 호출하면 새로운 Runnable 객체가 생성됨.
- inline 키워드를 사용하면 무명 클래스를 생성하지 않고 최적화 가능
5.4.2 SAM 생성자: 람다를 함수형 인터페이스로 명시적으로 변경
- SAM(Single Abstract Method) 인터페이스: 단 하나의 추상 메서드만 가진 인터페이스
- 자바에서는 람다를 사용하려면 함수형 인터페이스가 필요, 코틀린에서는 람다를 직접 함수로 사용
컴파일러가 자동으로 람다를 함수형 인터페이스 무명 클래스로 변환하지 못하는 경우에는 직접 변환을 도와주는 SAM 생성자를 사용할 수 있다.
SAM 생성자를 사용해 값 반환하기
fun createAllDoneRunnable(): Runnable {
return Runnable { println("All done!") }
}
fun main() {
createAllDoneRunnable().run() // 출력: All done!
}- SAM 생성자의 이름은 사용하려는 함수형 인터페이스의 이름과 같다.
- SAM 생성자는 그 함수형 인터페이스의 유일한 추상 메소드의 본문에 사용할 람다만을 인자로 받아서 함수형 인터페이스를 구현하는 클래스의 인스턴스를 반환한다.
- Runnable { println("All done!") } → SAM 생성자를 사용해 람다를 Runnable 객체로 변환
- createAllDoneRunnable() 함수는 Runnable을 반환하므로, run()을 호출하면 "All done!"이 출력됨.
- 람다는 익명 함수라서 직접 반환할 수 없음.
- SAM 생성자를 사용하면, 람다를 함수형 인터페이스로 변환하여 반환할 수 있음.
- SAM 생성자를 사용하는 이유 : 코틀린에서 자바 코드와의 상호운용성 때문일까?
SAM 생성자는 코틀린에서 자바의 함수형 인터페이스(SAM)를 사용할 때 주로 필요하지만, 코틀린 자체적인 이유로도 필요할 수 있다.
1. SAM 생성자가 필요한 이유
코틀린에서는 함수를 값처럼 다룰 수 있기 때문에 람다를 직접 반환할 수 있을 것 같지만,
자바의 함수형 인터페이스를 반환해야 하는 경우에는 변환 과정이 필요하다!
자바에서 함수형 인터페이스를 사용하는 경우
@FunctionalInterface
interface Runnable {
void run();
}
public class JavaInterop {
public static Runnable getRunnable() {
return () -> System.out.println("Hello from Java!");
}
}- Runnable은 자바의 함수형 인터페이스 (SAM)
- getRunnable() → 람다를 반환하지만, Runnable 타입으로 변환해야 함!
2. 코틀린에서는 람다를 직접 반환할 수 없을까?
코틀린에서는 람다 자체를 직접 반환하는 것은 불가능하다! 코틀린에서 람다는
일반적인 객체가 아니라 "익명 함수(Anonymous Function)"로 처리되기 때문이다.
잘못된 코드 (컴파일 오류 발생)
fun createAllDoneRunnable(): Runnable {
return { println("All done!") } // 오류 발생
}- return { println("All done!") } → 람다는 Runnable이 아니므로 반환 불가능하다
- 코틀린에서는 람다를 반환할 수 없기 때문에, 반드시 변환 과정이 필요함.
⇒ 그래서 SAM 생성자를 사용하면 해결할 수 있다!
3. SAM 생성자를 사용하면 해결 가능!
fun createAllDoneRunnable(): Runnable {
return Runnable { println("All done!") } // 올바른 코드
}- Runnable { println("All done!") } → SAM 생성자가 람다를 Runnable로 변환해줌.
- 이렇게 하면 코틀린에서 람다를 자바의 함수형 인터페이스로 변환할 수 있음!
4. SAM 생성자가 꼭 자바 코드와 관련이 있을까?
SAM 생성자는 주로 자바 함수형 인터페이스를 사용할 때 필요하지만,
코틀린에서도 람다를 특정 인터페이스 타입으로 변환해야 할 때 유용해.
코틀린에서 자체적으로 SAM 생성자가 필요할 수도 있다!
interface MyFunctionalInterface {
fun execute()
}
fun getFunction(): MyFunctionalInterface {
return MyFunctionalInterface { println("Executing function!") } // ✅ 가능
}
fun main() {
getFunction().execute() // 출력: Executing function!
}- MyFunctionalInterface { println("Executing function!") } → SAM 생성자를 사용해 람다를 인터페이스 구현체로 변환!
- 이처럼 자바가 아니라도, 함수형 인터페이스를 반환하려면 SAM 생성자가 필요할 수 있음.
5. 결론
- SAM 생성자는 코틀린에서 자바의 함수형 인터페이스(SAM)를 사용할 때 필요!
- Runnable, Callable, OnClickListener 같은 인터페이스를 사용할 때 자주 활용됨.
- 코틀린 자체적으로도 특정 함수형 인터페이스를 반환해야 할 때 유용!
- 자바가 아니더라도, 람다를 특정 인터페이스 타입으로 변환할 필요가 있을 때 SAM 생성자가 필요할 수 있음.
- 람다는 인터페이스가 아니므로 직접 반환할 수 없음.
- return { ... } → 오류 발생
- return Runnable { ... } → 올바른 방법 (SAM 생성자 사용)
SAM 생성자로 리스너 인스턴스 재사용하기
val listener = OnClickListener { view ->
val text = when (view.id) {
R.id.button1 -> "First button"
R.id.button2 -> "Second button"
else -> "Unknown button"
}
toast(text)
}
// 같은 리스너를 여러 버튼에 적용 가능!
button1.setOnClickListener(listener)
button2.setOnClickListener(listener)- 버튼 클릭 리스너 같은 이벤트 리스너를 여러 개의 UI 요소에서 공유해야 할 때,
- SAM 생성자를 사용하면 하나의 리스너 인스턴스를 재사용할 수 있어.
- OnClickListener { view -> ... } → SAM 생성자로 OnClickListener 객체 생성
- listener 변수에 저장하여 여러 버튼에서 재사용 가능!
- button1과 button2에 동일한 리스너를 설정할 수 있음.
SAM 생성자의 장점
- 여러 UI 요소에서 같은 리스너를 재사용 가능 → 메모리 절약 & 코드 중복 감소
- 컴파일러가 자동 변환하지 못하는 경우 명시적으로 변환 가능
리스너 등록/해제
val listener = object : OnClickListener {
override fun onClick(view: View) {
println("Button clicked!")
}
}
button.setOnClickListener(listener)
button.setOnClickListener(null) // 리스너 해제- 람다에는 무명 객체와 달리 this가 없기 때문에, 리스너 등록/해제가 어려울 수 있다!
- 이럴 때는 무명 객체를 사용해야 한다!
- object : OnClickListener { ... } → 무명 객체를 사용해서 리스너를 등록
- button.setOnClickListener(null) → 등록한 리스너를 해제 가능
이 방식이 필요한 이유
- 람다에는 this가 없어서, 리스너를 해제하려면 객체가 필요함.
- 무명 객체를 사용하면, 같은 객체를 참조하여 등록/해제 가능.
컴파일러가 자동 변환해 줄 수 없는 경우에는 명시적으로 SAM 생성자를 사용해야 한다.
- 예를 들어
- 람다를 반환해야 할 때 (return 키워드 사용)
- 여러 UI 요소에서 같은 리스너를 공유할 때
- 람다에 this가 없어서 특정 객체를 참조해야 할 때
팀원5 part (5.5 수신 객체 지정 람다: with와 apply)
- with와 apply는 코틀린 표준 라이브러리 → 매우 편리
- 이번 절에서는 자바의 람다에는 없는 코틀린 람다의 독특한 기능을 설명 → 수신 객체를 명시하지 않고 람다의 본문 안에서 다른 객체의 메소드를 호출할 수 있게 하는 것
- 그런 람다를 수신 객체 지정 람다(lambda with receiver)라고 부름
5.5.1 with 함수
- 어떤 객체의 이름을 반복하지 않고도 그 객체에 대해 다양한 연산을 수행할 수 있다면 좋을 것 → with라는 라이브러리 함수
fun alphabet (): String {
val result = StringBuilder()
for (letter int 'A'..'Z') {
result.append(letter)
}
result.append("\nNow I know the alphabet!")
return result.toString()
}
>>> println(alphabet())
ABCDEFGHIJKLMNOPQRSTUVWXYZ
Now I know the alphabet!- 이 예제에서 result에 대해 여러 메소드를 호출하면서 매번 result를 반복 사용 → result를 더 자주 반복해야 했다면 좀 그럼
fun alphabet(): String {
val stringBuilder = StringBuilder()
return with(stringBuilder) { // 메소드를 호출하려는 수신 객체 지정
for (letter in 'A'..'Z') {
this.append(letter) // "this"를 명시해서 앞에서 지정한 수신 객체 호출
}
append("\nNow I know the alphabet!") // "this"를 생략하고 메소드 호출
this.toString() // 람다에서 값을 반환
}
}- with문은 파라미터가 2개 있는 함수 → 첫 번째 파라미터는 stringBuilder이고, 두 번째 파라미터는 람다
- stringBuilder의 메소드를 this.append(letter)처럼 this 참조를 통해 접근하거나 append(”\nNow…”)처럼 바로 호출할 수 있음
inline fun <T, R> with(receiver: T, block: T.() -> R): R- with 함수는 첫 번째 인자로 받은 객체를 두 번째 인자로 받은 람다의 수신 객체로 만듬
- 인자로 받은 람다 본문에서는 this를 사용해 그 수신 객체에 접근
- 일반적인 this와 마찬가지로 this와 점(.)을 사용하지 않고 프로퍼티나 메소드 이름만 사용해도 수신 객체의 멤버에 접근할 수 있음

- 앞의 alphabet 함수를 더 리팩토링해서 불필요한 stringBuilder 변수를 없앨 수도 있음
fun alphabet () = with(StringBuilder()) {
for (letter in 'A'..'Z') {
append(letter)
}
append("\nNow I know the alphabet!")
toString()
}- 불필요한 stringBuilder 변수를 없애면 alphabet 함수가 식의 결과를 바로 반환하게 됨 → 식을 본문으로 하는 함수로 표현 가능
- StringBuilder의 인스턴스를 만들고 즉시 with에게 인자로 넘기고, 람다 안에서 this를 사용해 그 인스턴스를 참조
val person = Person("Alice", 25)
val description = with(person) {
println("이름: $name")
"나이: ${age}세"
}
// 콘솔에 이름이 출력되고, descripption엔 나이가 저장됨
class OuterClass {
fun toString(): String {
return "OuterClass의 toString"
}
fun alphabet(): String {
return with(StringBuilder()) {
append("ABC")
// 만약 여기서 OuterClass의 toString을 부르고 싶다면?
this@OuterClass.toString()
//this.toString() 만 하면 StringBuilder.toString이 호출됨
}
}
}- with가 반환하는 값은 람다 코드를 실행한 결과며, 그 결과는 람다 식의 본문에 있는 마지막 식의 값
- 하지만 때로는 람다의 결과 대신 수신 객체가 필요한 경우도 있음
5.5.2 apply 함수
- apply 함수는 with와 거의 같음 → 유일한 차이는 apply는 항상 자신에게 전달된 객체(수신객체)를 반환한다는 점
fun alphabet () = StringBuilder().apply{
for (letter in 'A'..'Z') {
append(letter)
}
append("\nNow I know the alphabet!")
}.toString()- apply는 확장 함수로 정의돼 있음 → apply의 수신 객체가 전달받은 람다의 수신 객체가 됨
- 이 함수에서 apply를 실행한 결과는 StringBuilder 객체 → 그 객체의 toString을 호출해서 String 객체를 얻을 수 있음
inline fun <T> T.apply(block: T.() -> Unit): T- with와 같이 apply도 this 생략 가능
val person = Person().apply {
name = "Bob"
age = 30
}
// person 객체가 그대로 반환
// val person = Person("Bob", 30)과 무슨 차이?
// 생성자에 파라미터가 많지 않고 단순히 초기값을 넣는 경우엔 주 생성자로 직접 할당하는 것이 더 간결하지만, 생성 로직이 복잡하거나, 프로퍼티를 여러 단계에 걸쳐 초기화해야 경우엔 apply를 사용하면 가독성이 높아짐
// 예: 여러 프로퍼티를 단계별로 설정하거나, 추가적인 메소드를 호출해야 할 때- apply 함수는 객체의 인스턴스를 만들면서 즉시 프로퍼티 중 일부를 초기화 하는 경우 유용
- 자바에서는 보통 별도의 Builder 객체가 이런 역할을 담당
- 코틀린에서는 어떤 클래스가 정의돼 있는 라이브러리의 특별한 지원 없이도 그 클래스 인스턴스에 대해 apply를 활용할 수 있음
fun createViewWithCustomAttributes(context: Context) =
TextView(context).apply {
text = "Sample Text"
textSize = 20.0
setPadding(10, 0, 0, 0)
}- apply 함수를 사용하면 함수의 본문에 간결한 식을 사용할 수 있음
- 새로운 TextView 인스턴스를 만들고 즉시 그 인스턴스를 apply에 넘김
- apply에 전달된 람다 안에서는 TextView가 수신 객체가 됨 → 원하는 대로 TextView의 메소드를 호출하거나 프로퍼티를 설정할 수 있음
- 람다를 실행하고 나면 apply는 람다에 의해 초기화된 TextView 인스턴스를 반환하고 그 인스턴스는 createViewWithCustomAttributes 함수의 결과가 됨
fun alphabet () = buildString {
for (letter in 'A' .. 'Z') {
append(letter)
}
append("\nNow I know the alphabet!")
}- with와 apply는 수신 객체 지정 람다를 사용하는 일반적인 예제 중 하나 → 더 구체적인 함수를 비슷한 패턴으로 활용 가능
- 표준 라이브러리의 buildString 함수를 사용하면 alphabet 함수를 더 단순화할 수 있음
- buildString은 앞에서 살펴 본 alphabet 코드에서 StringBuilder 객체를 만드는 일과 toString을 호출해주는 일을 알아서 해줌
- buildString의 인자는 수신 객체 지정 람다며, 수신 객체는 항상 StringBuilder가 됨 → StringBuilder를 활용해 String을 만드는 경우 사용할 수 있는 우아한 해법
도서 링크 바로가기
https://product.kyobobook.co.kr/detail/S000001804588
Kotlin in Action | 드미트리 제메로프 - 교보문고
Kotlin in Action | 코틀린이 안드로이드 공식 언어가 되면서 관심이 커졌다. 이 책은 코틀린 언어를 개발한 젯브레인의 코틀린 컴파일러 개발자들이 직접 쓴 일종의 공식 서적이라 할 수 있다. 코틀
product.kyobobook.co.kr
'Programming Language > Kotlin' 카테고리의 다른 글
| [Kotlin In Action] 7장. 연산자 오버로딩과 기타 관례 정리 feat. 내가 정리한 부분만 (0) | 2025.04.03 |
|---|---|
| [Kotlin In Action] 6장. 코틀린 타입 시스템 정리 feat. 내가 정리한 부분만 (0) | 2025.04.03 |
| [Kotlin In Action] 4장. 클래스 , 객체 , 인터페이스 정리 (0) | 2025.03.21 |
| [Kotlin In Action] 3장. 함수 정의와 호출 정리 (0) | 2025.03.20 |
| [Kotlin In Action] 2장. 코틀린 기초 스터디 정리 (0) | 2025.03.01 |
Kotlin in Action을 공부하며 정리한 내용입니다.
저작권에 문제가 될 시, 글을 모두 내리겠습니다.
제가 공부한 내용이 더 많은 분들에게도 도움이 되었으면 좋겠습니다. 부족한 부분은 댓글을 통해서 피드백을 주신다면 언제나 반영하겠습니다. 감사합니다.
책에 대한 링크는 맨 아래에 있습니다.
https://github.com/Kotlin-Android-Study-with-SSAFY/Kotlin_In_Action_1
GitHub - Kotlin-Android-Study-with-SSAFY/Kotlin_In_Action_1: SSAFY 13기 모바일 트랙 구미 5반 "코틀린 인 액션" 스
SSAFY 13기 모바일 트랙 구미 5반 "코틀린 인 액션" 스터디(A). Contribute to Kotlin-Android-Study-with-SSAFY/Kotlin_In_Action_1 development by creating an account on GitHub.
github.com
내가 정리한 Part (5.1 람다식과 멤버 참조)
들어가기 용어 초 간단 정리
- 람다란 익명 함수(anonymous function) 의 일종으로, 함수의 이름 없이 정의할 수 있는 간결한 표현 방식이다.
- 고차함수란 다른 함수를 매개변수로 받거나 반환하는 함수를 의미한다.
- 1급 객체(First-Class Citizen)란 프로그래밍 언어에서 특정 요소(예: 변수, 함수 등)를 값처럼 취급할 수 있는 개념을 의미한다.
5.1.1 람다 소개: 코드 블록을 함수 인자로 넘기기
자바에서는 특정 이벤트 발생 시 실행할 동작을 정의하기 위해 무명 내부 클래스를 사용했지만, 이는 코드가 번잡해지는 단점이 있다. 반면, 함수형 프로그래밍에서는 함수를 값처럼 다룰 수 있어 코드가 간결해진다.
람다 식을 사용하면 클래스를 선언할 필요 없이 코드 블록을 직접 함수의 인자로 전달할 수 있다. 예를 들어, 버튼 클릭 이벤트를 처리하는 리스너를 추가할 때 자바에서는 아래처럼 작성해야 한다.
/* 자바 */
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View view) {
/* 클릭 시 수행할 동작 */
}
});무명 내부 클래스를 사용하면 코드가 복잡해지며, 여러 곳에서 반복 사용되면 가독성이 떨어진다.
코틀린에서는 람다를 활용해 더욱 간결한 코드 작성이 가능하다.
/* 코틀린 */
button.setOnClickListener { /* 클릭 시 수행할 동작 */ }이 코드도 동일한 동작을 수행하지만, 더욱 간결하고 직관적이다. 이처럼 코틀린 람다는 메소드가 하나뿐인 인터페이스(예: 클릭 리스너)를 대체할 수 있으며, 코드의 가독성과 유지보수성을 높이는 데 유용하다.
5.1.2 람다와 컬렉션
코드에서 중복을 제거하는 것은 프로그래밍 스타일을 개선하는 중요한 방법 중 하나다. 특히 컬렉션을 다룰 때 반복되는 패턴이 많기 때문에, 이를 효율적으로 처리할 수 있는 라이브러리 함수가 필요하다.
코틀린에서는 컬렉션을 쉽게 다룰 수 있는 람다 기반의 라이브러리 함수가 제공되므로, 직접 구현할 필요가 없다.
=> 많이 사용해보자.
fun findTheOldest(people: List<Person>) {
var maxAge = 0
var theOldest: Person? = null
for (person in people) {
if (person.age > maxAge) {
maxAge = person.age
theOldest = person
}
}
println(theOldest)
}위 코드는 people 리스트에서 가장 나이가 많은 사람을 찾는 코드이다. 그러나 반복문과 변수 변경이 많아 가독성이 떨어진다.
println(people.maxBy { it.age })위 코드처럼 maxBy 함수를 사용하면 한 줄로 동일한 동작을 수행할 수 있다.
{ it.age }는 Person 객체의 age 프로퍼티를 기준으로 비교하도록 한다.- it 키워드는 컬렉션의 각 원소(Person)를 가리킨다.
더더더더 간결한 코드
people.maxBy(Person::age){ it.age }대신 멤버 참조(Person::age)를 사용하면 더욱 직관적인 코드가 된다.- 이는 Person 클래스의 age 프로퍼티를 기준으로 최댓값을 찾는 기능을 수행한다.
- 결론 람다는 신이댜.
5.1.3 람다 식의 문법
코틀린 람다는 항상 중괄호{} 로 감싸며, 괄호 없이 매개변수를 정의하고 화살표(->) 로 본문과 구분한다.
람다가 변수에 저장되면 일반 함수처럼 호출할 수 있다.
>>> { println(42) } ()
42
>>> run { println(42) }
42{ println(42) } ()→ 람다를 즉시 실행run { println(42) }→ run 함수를 사용하여 람다 실행- 괄호를 굳이 붙이지 않아도 됨.
람다는 다른 함수의 인자로 전달될 수 있다.
people.maxBy({ p: Person -> p.age })위 코드에서 { p: Person -> p.age }는 Person 타입의 인자를 받아 age 값을 반환하는 람다이다.
하지만 이 방식은 괄호와 중괄호가 많아 가독성이 떨어진다. =>
people.maxBy() { p: Person -> p.age } // 람다를 괄호 밖으로 이동
people.maxBy { p: Person -> p.age } // 유일한 인자라면 괄호 생략 가능- 람다가 유일한 인자라면 괄호를 생략하는 것이 일반적이다.
joinToString 함수는 컬렉션 원소를 문자열로 변환하는 함수이다. (3장에서 해봄)
람다를 활용하면 각 원소를 특정 방식으로 변환할 수 있다.
>>> val people = listOf(Person("이몽룡", 29), Person("성춘향", 31))
>>> val names = people.joinToString(separator = " ", transform = { p: Person -> p.name })
>>> println(names)이를 괄호 밖으로 빼면 더 간결해진다.
위 코드에서 transform 인자로 { p: Person -> p.name } 람다를 전달하여
각 Person 객체의 name만 추출하고 공백으로 연결한다.
people.joinToString(" ") { p: Person -> p.name }람다가 마지막 인자이므로 괄호 밖으로 이동할 수 있다.
람다에서 매개변수의 타입을 생략*할 수 있다.
코틀린 컴파일러가 문맥을 분석하여 자동으로 타입을 추론하기 때문이다.
people.maxBy { p -> p.age } // Person 타입을 컴파일러가 추론 가능maxBy는 Person 타입의 컬렉션에서 사용되므로, p는 Person 타입으로 자동 추론된다.
람다의 매개변수가 하나일 때는 it 키워드를 사용할 수 있다.
people.maxBy { it.age } // it을 사용하여 더 간결하게 표현 가능it은 람다의 유일한 매개변수일 때 자동으로 생성되는 이름이다.
But it의 사용은 정말 간단할 때만 사용한다.
it 키워드는 람다의 매개변수가 하나일 때 자동으로 제공되는 암시적 변수이다. 하지만 모든 경우에 it을 사용하는 것이 최선은 아니다.
// it을 써도 좋은 예시
val numbers = listOf(1, 2, 3, 4, 5)
val evenNumbers = numbers.filter { it % 2 == 0 }
println(evenNumbers) // 결과: [2, 4]- 가독성을 크게 해치지 않는다.
// it을 쓰면 나쁜 경우
val people = listOf(Person("Alice", 29), Person("Bob", 31))
val adults = people.filter { it.age > 18 && it.name.startsWith("A") }
// 개선 코드
val adults = people.filter { person -> person.age > 18 && person.name.startsWith("A") }- it이 Person 객체를 가리킨다는 것이 명확하지 않다.
- 나중에 코드가 복잡해지면 어떤 속성을 참조하는지 파악하기 어려울 수 있다.
람다를 변수에 저장할 때는 타입 명시 필요
>>> val getAge = { p: Person -> p.age }
>>> people.maxBy(getAge)- 람다를 변수에 저장할 때는 컴파일러가 타입을 추론할 문맥이 없으므로 타입을 명시해야한다.
람다는 여러 줄로 구성될 수도 있으며, 마지막 표현식의 결과가 반환된다.
>>> val sum = { x: Int, y: Int ->
println("Computing the sum of $x and $y...")
x + y
}
>>> println(sum(1, 2))
Computing the sum of 1 and 2...
3
5.1.4 현재 영역에 있는 변수에 접근
코틀린의 람다는 외부 함수의 변수를 포획(capture)하여 사용할 수 있으며, 그 값을 변경할 수도 있다.
이는 클로저(closure) 라고 불리며, 함수 실행이 끝난 후에도 포획한 변수가 유지되는 특징을 가진다.
람다는 함수 내부에서 선언된 변수뿐만 아니라, 함수의 매개변수에도 접근 가능하다.
fun printMessagesWithPrefix(messages: Collection<String>, prefix: String) {
messages.forEach {
println("$prefix $it")
}
}- prefix는 함수 매개변수이지만, forEach 람다 내부에서 자유롭게 사용 가능
- 이는 람다가 외부 변수(prefix)를 포획하여 접근할 수 있기 때문
자바와 다르게 코틀린에서는 람다 내부에서 외부 변수 값을 변경할 수도 있다.
fun printProblemCounts(responses: Collection<String>) {
var clientErrors = 0
var serverErrors = 0
responses.forEach {
if (it.startsWith("4")) {
clientErrors++
} else if (it.startsWith("5")) {
serverErrors++
}
}
println("$clientErrors client errors, $serverErrors server errors")
}
>>> val responses = listOf("200 OK", "418 I'm a teapot", "500 Internal Server Error")
>>> printProblemCounts(responses)
// 결과: 1 client errors, 1 server errors- clientErrors와 serverErrors는 람다 내부에서 변경되지만, 외부 변수이므로 값이 유지됨
- 람다가 이 변수를 포획(Capture) 했기 때문에, 함수 실행 후에도 값이 변경된 상태로 유지
람다는 함수 실행이 끝나도 포획한 변수를 계속 유지할 수 있다.
즉, 람다가 종료된 후에도 변수 값을 읽고 수정할 수 있는 구조를 클로저(Closure) 라고 한다.
fun main() {
var counter = 0 // 람다가 포획할 변수
val increment: () -> Unit = { counter++ } // counter 변수 포획
increment()
increment()
println(counter) // 결과: 2 (counter 값이 유지됨)
}increment()실행 시 counter 값이 증가하며, 람다 실행이 끝나도 변수 값이 유지됨
포획된 변수는 람다가 유지되는 한 계속 사용 가능하다.
fun createCounter(): () -> Int {
var count = 0 // 포획할 변수
return { ++count } // 람다가 count를 포획
}
fun main() {
val counter1 = createCounter()
val counter2 = createCounter()
println(counter1()) // 결과: 1
println(counter1()) // 결과: 2
println(counter2()) // 결과: 1 (새로운 클로저)
}- counter1()과 counter2()는 서로 다른 람다 인스턴스를 사용하므로 독립적인 count 값을 유지
람다 내부에서 외부 리스트에 값을 추가하는 경우, 리스트 자체가 포획되어 유지된다.
fun main() {
val clientErrors = mutableListOf<Int>()
val serverErrors = mutableListOf<Int>()
val processError: (Int) -> Unit = { code ->
if (code in 400..499) clientErrors.add(code) // clientErrors 포획
else if (code in 500..599) serverErrors.add(code) // serverErrors 포획
}
processError(404)
processError(500)
processError(403)
println("Client Errors: $clientErrors") // 결과: [404, 403]
println("Server Errors: $serverErrors") // 결과: [500]
}- 외부 리스트(clientErrors, serverErrors)가 람다에 의해 포획되었기 때문에 함수 실행 후에도 값이 유지됨
- 람다를 비동기적으로 실행할 경우, 함수 실행이 끝난 후에도 로컬 변수가 남아 예상과 다른 결과를 초래할 수 있다.
fun tryToCountButtonClicks(button: Button): Int {
var clicks = 0
button.onClick { clicks++ }
return clicks
}
문제점
- onClick 핸들러는 tryToCountButtonClicks()가 끝난 후 실행되므로, clicks++이 실행되어도 함수가 반환한 값에는 반영되지 않는다.
- 항상 0을 반환하게 된다
해결 방법
- 클래스의 프로퍼티나 전역 변수로 clicks 값을 관리하면 해결 가능
class ClickCounter { var clicks = 0 fun registerClickHandler(button: Button) { button.onClick { clicks++ } } }- 이렇게 하면 clicks 변수가 함수 실행과 독립적으로 유지되어 정상 동작함
5.1.5 멤버 참조
람다를 사용하면 코드 블록을 함수의 인자로 전달할 수 있다. 하지만 이미 선언된 함수를 사용할 경우, 람다를 만들지 않고 직접 전달하는 방법이 있을까?
코틀린에서는 이중 콜론(::)을 사용하여 함수나 프로퍼티를 값처럼 다룰 수 있다.
이것을 멤버 참조(Member Reference) 라고 한다.
val getAge = Person::agePerson::age는 Person 객체의 age 프로퍼티를 참조하는 멤버 참조이다.- 이는
{ p -> p.age }람다와 같은 역할을 한다.
멤버 참조는 람다와 같은 역할을 수행할 수 있으며, 더 간결한 표현이 가능하다.
people.maxBy { p -> p.age } // 람다 사용
people.maxBy { it.age } // 람다에서 'it' 사용
people.maxBy(Person::age) // 멤버 참조 사용 (더 간결함)- Person::age는 { p -> p.age } 람다와 동일한 기능을 수행
- 더 짧고 가독성이 좋은 멤버 참조를 활용하면 코드가 간결해진다.
클래스 멤버뿐만 아니라, 최상위에 선언된 함수도 멤버 참조로 사용할 수 있다.
fun salute() = println("Salute!")
>>> run(::salute)
Salute!- ::salute를 run 함수에 전달하여 실행
- run은 전달받은 함수(람다)를 실행하는 역할을 한다.
람다가 단순히 다른 함수에 작업을 위임하는 경우, 람다를 정의할 필요 없이 멤버 참조를 직접 사용할 수 있다.
val action = { person: Person, message: String -> sendEmail(person, message) }
val nextAction = ::sendEmail // 멤버 참조 사용- { person, message -> sendEmail(person, message) } 람다는 불필요한 중복이 발생
- ::sendEmail로 더 간결하게 표현 가능
생성자를 참조할 수도 있다. 생성자를 변수에 저장하거나, 지연 초기화할 때 유용하다.
data class Person(val name: String, val age: Int)
>>> val createPerson = ::Person
>>> val p = createPerson("Alice", 29)
>>> println(p)
Person(name=Alice, age=29)- ::Person은 Person 클래스의 생성자를 참조
- createPerson("Alice", 29)를 호출하면 Person 객체가 생성됨
확장 함수도 멤버 참조를 통해 참조할 수 있다.
fun Person.isAdult() = age >= 21
val predicate = Person::isAdult- Person::isAdult는 확장 함수를 참조하는 방식
- predicate(Alice)처럼 사용 가능
팀원2 Part (5.2 컬렉션 함수형 API)
- filter와 map은 컬렉션을 활용할 때 기반이 되는 함수 → 대부분의 컬렉션 연산을 이 두 함수를 통해 표현 가능
고차함수(HOF, High Order Function) : 함수형 프로그래밍에서 람다나 다른 함수를 인자로 받거나 함수를 반환하는 함수
- 장점 : 기본 함수를 조합해서 새로운 연산을 정의 or 다른 고차 함수를 통해 조합된 함수를 또 조합해서 더 복잡한 연산을 쉽게 정의 가능
- 컴비네이터 패턴(combinator pattern) : 고차함수와 단순한 함수를 이리저리 조합해서 코드를 작성하는 기법
- 컴비네이터(combinator) : 컴비네이터 패턴에서 복잡한 연산을 만들기 위해 값이나 함수를 조합할 때 사용하는 고차 함수
- filter 함수 : 컬렉션을 이터레이션하면서 주어진 람다에 각 원소를 넘겨서 람다가 true를 반환하는 원소만 모음
>>> val list = listOf(1, 2, 3, 4)
>>> println(list.filter {it % 2 == 0}) <-짝수만 남음
**[2, 4]**- filter 함수는 컬렉션에서 원치 않는 원소를 제거한다. 하지만 filter는 원소를 변환 불가능하다. 원소를 변환하려면 map 함수를 사용
- map 함수 : 주어진 람다를 컬렉션의 각 원소에 적용한 결과를 모아서 새 컬렉션을 만듦
>>> val list = listOf(1, 2, 3, 4)
>>> println(list.map { it * it })
[1, 4, 9, 16]
- 사람의 리스트가 아니라 이름의 리스트를 출력하고 싶다면 map으로 사람의 리스트를 이름의 리스트로 변환
>>> val people = listOf (Person("Alice", 29), Person("Bob", 31))
>>> println (people.map { it.name })
[Alice, Bob]people.map(Person::name)>>> (people.filter({it.age > 30 })).map(Person::name) <- 괄호를 명확히 사용
>>> people.filter{ it.age > 30 }.map(Person::name) <- 구문을 훨씬 간결하게 표현 가능
[Bob]
가장 나이 많은 사람의 이름을 알고 싶을 경우
<일반적인 방법>
- 목록에 있는 사람들의 나이의 최대값 구하기
- 나이가 그 최댓값과 같은 모든 사람 반환
people.filter { it.age == people.maxBy (Person::age)!!.age }→ 단점 : 목록에서 최댓값을 구하는 작업을 계속 반복(100명일 경우 100번 반복)
- 개선 방법 : 최댓값을 한 번만 계산
val maxAge = people.maxBy(Person::age) !!.age
people.filter { it.age == maxAge }꼭 필요하지 않은 경우 굳이 계산을 반복하지 말라! 인자로 받는 함수에 람다를 넘기면 겉으로 볼 때 단순해 보이는 식이 내부 로직의 복잡도로 인해 실제로는 엄청나게 불합리한 계산식이 될 때가 있음
- 필터와 변환 함수를 맵(키와 값을 연관시켜주는 데이터 구조)에 적용 가능
>>> val numbers = mapOf(0 to "zero", 1 to "one")
>>> println(numbers.mapValues { it.value.toUpperCase() })
{0=ZERO, 1=ONE}- 맵의 경우 키와 값을 처리하는 함수 따로 존재
- 키를 걸러 내거나 변환 : filterKeys, mapKeys
- 값을 걸러 내거나 변환 : filterValues, mapValues
5.2.2 all, any, count, find : 컬렉션에 술어 적용
- all, any : 컬렉션의 모든 원소가 어떤 조건을 만족하는지 판단(또는 컬렉션 안에 어떤 조건을 만족하는 원소가 있는지 판단) → true / false
- count : 조건을 만족하는 원소의 개수를 반환
- find : 조건을 만족하는 첫 번째 원소 반환
val canBeInClub27 = { p: Person -> p.age <= 27 }
- 모든 원소가 이 술어를 만족하는 지 궁금할 경우
>>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
>>> println(people.all(canBeInClub27))
false- 술어를 만족하는 원소가 하나라도 있는 지 궁금할 경우
>>> println(people.any(canBeInClub27))
true
드 모르강의 법칙(De Morgan’s Theorem)
- 어떤 조건에 대해 !all을 수행한 결과가 그 조건의 부정에 대해 any를 수행한 결과는 같음
- 어떤 조건에 대해 !any를 수행한 결과와 그 조건의 부정에 대해 all을 수행한 결과도 같음
→ 가독성을 높이려면 any와 all 앞에 !를 붙이지 않는 편이 나음
>>> val list = listOf(1, 2, 3)
>>> println(!list.all { it == 3 })
true>>> val list = listOf(1, 2, 3)
>>> println(list.any { it != 3 })
true- 술어를 만족하는 원소의 개수 구하려는 경우
>>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
>>> println(people.count(canBeInClub27))
1
함수를 적재적소에 사용하라 : count와 size
- count가 있다는 사실을 잊고, 컬렉션을 필터링한 결과의 크기를 가져오는 경우가 있음
>>> println (people.filter(canBeInClub27).size)
1- 하지만 이렇게 처리하면 조건을 만족하는 모든 원소가 들어가는 중간 컬렉션이 생긴다. 반면 count는 조건을 만족하는 원소의 개수만을 추적함. 조건을 만족하는 원소를 따로 저장하지 않는다. 따라서 count가 훨씬 더 효율적임
- 술어를 만족하는 원소를 하나 찾고 싶은 경우
>>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
>>> println (people.find(canBeInClub27))
Person (name=Alice, age=27)- 이 식은 조건을 만족하는 원소가 하나라도 있는 경우 → 가장 먼저 조건을 만족한다고 확인된 원소를 반환
- 만족하는 원소가 없는 경우 → null 반환
- groupby : 특성을 파라미터로 전달하면 컬렉션을 자동으로 구분해주는 함수
>>> val people = listOf (Person("Alice", 31),
... Person("Bob", 29), Person("Carol", 31))
>>> println (people.groupBy { it.age })
{29=[Person (name=Bob, age=29)],
31=[Person (name=Alice, age=31), Person (name=Carol, age=31)]}- 연산의 결과 → 컬렉션의 원소를 구분하는 특성이 키이고, 키 값에 따른 각 그룹이 값인 맵
- groupBy의 결과 타입 → Map<Int, List<Person>>
>>> val list = listOf("a", "ab", "b")
>>> println(list.groupBy(String::first))
{a=[a, ab], b=[b) }- first는 String의 멤버가 아닌 확장 함수이지만 여전히 멤버 참조를 사용해 first에 접근 가능
5.2.4 flatMap과 flatten : 중첩된 컬렉션 안의 원소 처리
- Book으로 표현한 책에 대한 정보를 저장하는 도서관이 있다고 가정
class Book(val title: String, val authors: List<String>)- 책마다 저자가 한 명 또는 여러 명 존재
books.flatMap { it.authors }.toSet()- flatMap 함수로 먼저 인자로 주어진 람다를 컬렉션의 모든 객체에 적용하고(또는 매핑하기 map) 람다를 적용한 결과 → 여러 리스트를 한 리스트로 모음(또는 펼치기 flatten)
>>> val strings = listOf("abc", "def")
>>> println(strings.flatMap { it.toList() })
[a, b, c, d, e, f]- toList 함수 : 문자열에 적용하면 그 문자열에 속한 모든 문자로 이뤄진 리스트가 만들어짐
- flatMap 함수 : 다음 단계로 리스트의 리스트에 들어있던 모든 원소로 이뤄진 단일 리스트 반환
>>> val books = listOf (Book("Thursday Next", listOf ("Jasper Fforde")),
Book ("Mort", listOf("Terry Pratchett")),
Book ("Good Omens", listOf("Terry Pratchett",
"Neil Gaiman")))
>>> println (books.flatMap { it.authors }.toSet())
[Jasper Fforde, Terry Pratchett, Neil Gaiman]- 상단 코드 설명
- book.authors 프로퍼티는 작가를 모아둔 컬렉션
- flatMap 함수는 모든 책의 작가를 평평한(문자열로만 이뤄진) 리스트 하나로 모음
- toSet 함수는 flatMap의 결과 리스트에서 중복을 없애고 집합을 만듦
- flatMap의 용도 : 리스트의 리스트가 있는데 모든 중첩된 리스트의 원소를 한 리스트로 모아야 할 경우
- flatten 함수 : 특별히 변환해야 할 내용이 없다면 리스트의 리스트를 평평하게 펼치기만 하면 되는 경우 → 사용법 : listOfLists.flatten()
flatMap vs flatten vs map 차이점 정리
| 함수 | 기능 | 변환 가능? | 예제 입력 | 결과 |
| flatMap | 변환 후 평탄화 | 가능 | listOf(1, 2, 3),flaMap { listOf(it, it * 10) } | [1, 10, 2, 20, 3, 30] |
| flatten | 평탄화만 수행 | 불가능 | listOf(listOf(1, 2), listOf(3, 4)).flatten() | [1, 2, 3, 4] |
| map | 변환만 수행(평탄화 없음) | 가능 | listOf("abc", "def").map { it.toList() } | [[a, b, c], [d, e, f]] |
팀원3 Part (5.3 지연 계산(Lazy) 컬렉션 연산)
즉시 실행 vs 지연 실행
기본적으로 map이나 filter 같은 컬렉션 연산은 즉시 실행 방식으로 동작한다. 즉, 각 연산이 수행될 때마다 새로운 리스트를 생성하여 결과를 저장한다.
val people = listOf(Person("Alice", 29), Person("Bob", 31), Person("Charles", 31), Person("Dan", 21))
val names = people.map { it.name }.filter { it.startsWith("A") }
println(names) // [Alice]위 코드의 문제점:
- map { it.name }을 실행하면 새로운 리스트가 생성됨.
- filter { it.startsWith("A") }을 실행할 때 또 새로운 리스트가 생성됨.
- 즉, 중간 결과를 저장하는 불필요한 리스트가 계속 만들어짐 → 비효율적!
시퀀스(Sequence) 를 사용하면 이러한 중간 컬렉션을 생성하지 않고도 연산을 연쇄적으로 적용할 수 있다.
val namesLazy = people.asSequence()
.map { it.name }
.filter { it.startsWith("A") }
.toList()
println(namesLazy) // [Alice]어떤 차이가 있을까?
- asSequence()를 사용하면 시퀀스 변환 후 지연 계산 방식으로 동작한다.
- 중간 연산(map, filter)은 실제로 데이터를 처리하지 않고, 최종 연산(toList())이 호출될 때 연산이 수행됨.
- 불필요한 중간 리스트가 만들어지지 않으므로 메모리 사용량이 줄어들고 성능이 개선됨
시퀀스 연산 실행 순서
아래 코드를 실행하면 연산이 수행되는 순서를 확인할 수 있다.
listOf(1, 2, 3, 4).asSequence()
.map { print("map($it) "); it * it }
.filter { print("filter($it) "); it % 2 == 0 }
.toList()출력 결과
map(1) filter(1) map(2) filter(4) map(3) filter(9) map(4) filter(16)
| 방식 | 즉시 실행 방식 ( List ) | 지연 실행 방식 (Sequence ) |
| 연산 방식 | map 실행 후 모든 요소 변환 -> filter 실행 | map 실행 후 즉시 filter 적용 |
| 중간 컬렉션 | map 실행 후 새로운 리스트 실행 | 중간 리스트 없이 연산 수행 |
| 연산 순서 | 모든 요소 변환 후 필터링 | 한 요소씩 변환 후 필터링 |
| 효율성 | 데이터가 많아질수록 불필요한 연산 증가 | 불필요한 연산이 최소화 됨 |
즉시 실행 방식 문제점
- map이 모든 요소에 대해 변환을 수행한 후 새로운 리스트 생성.
- filter가 새로운 리스트를 다시 필터링하면서 추가적인 연산 수행.
- 중간 결과를 저장하는 리스트가 계속 만들어져 메모리 낭비 발생
지연 실행 방식의 장점
- map과 filter가 각 요소별로 차례로 실행됨.
- 중간 리스트를 만들지 않고 바로 연산을 수행하여 메모리 절약 & 성능 향상
5.3.1 generateSequence를 이용한 무한 시퀀스 생성
일반 리스트(List<Int>)는 고정된 크기를 갖지만, 시퀀스는 필요할 때만 값을 생성하고 사용할 수 있음.
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo100 = naturalNumbers.takeWhile { it < 100 }
println(numbersTo100.sum()) // 5050- generateSequence(0) { it + 1 }
- 0부터 시작해서 1씩 증가하는 무한 시퀀스를 생성.
- takeWhile { it < 100 }
- 100보다 작은 숫자까지만 가져옴.
- sum()
- 최종 연산이 호출될 때까지 연산이 수행되지 않음.
일반 리스트를 사용하면 100개의 요소를 미리 생성해야 하지만, 시퀀스를 사용하면 필요한 만큼만 계산하여 성능이 더 우수하다.
5.3.2 디렉터리 탐색에 시퀀스 활용
파일 시스템을 탐색할 때, 특정 파일이 숨김 폴더 안에 있는지 확인하고 싶을 수 있다.
이럴 때 시퀀스를 사용하면 부모 폴더를 하나씩 탐색하며 조건을 만족하는지 검사할 수 있다.
fun File.isInsideHiddenDirectory(): Boolean =
generateSequence(this) { it.parentFile }.any { it.isHidden }
val file = File("/Users/svtk/.HiddenDir/a.txt")
println(file.isInsideHiddenDirectory()) // true- generateSequence(this) { it.parentFile }
- 현재 파일(this)에서 부모 디렉터리를 따라 올라가는 시퀀스를 생성.
- .any { it.isHidden }
- 부모 폴더 중 하나라도 숨김 폴더라면 true 반환.
- 숨김 폴더를 찾으면 즉시 탐색 종료 → 불필요한 연산 방지
기존 방식처럼 모든 부모 디렉터리를 리스트에 저장할 필요 없이, 조건을 만족하면 바로 탐색을 종료할 수 있다.
팀원4 part (5-4. 자바 함수형 인터페이스 활용)
우리가 다뤄야 하는 API 중 상당수는 코틀린이 아니라 자바로 작성된 API일 가능성이 높다. 다행인 점은 코틀린 람다를 자바 API에 사용해도 아무 문제가 없다는 사실이다.
button.setOnCllickListener(/* 클릭 시 실행할 동작 */);- 버튼(Button)을 클릭했을 때 실행할 동작을 정해주기 위해 setOnClickListener 메서드를 사용
- setOnClickListener 메서드의 인자(매개변수)로 OnClickListener 인터페이스 타입의 객체를 넘겨줘야 한다.
Button 클래스
public class Button{
public void setOnClickListener(OnClickListener 1){...}
}
onClickListener 인터페이스
public interface OnClickListener{
void onClick(View v);
}- OnClickListener는 onClick(View v)라는 메소드만 선언된 인터페이스
- 버튼을 클릭했을 때 실행할 동작을 정의하려면 OnClickListener를 구현한 객체를 만들어야 한다!
자바 8 이전의 방식(익명 클래스 사용)
button.setOnClickListener(new OnClickListener(){
@Override
public void onClick(View v){
//버튼 클릭 시 실행할 코드
System.out.println("버튼이 클릭됨!");
}
});- 자바 8 이전에는 인터페이스를 직접 구현한 익명 클래스를 만들어서 버튼 클릭 이벤트를 처리했다.
- new OnClickListener() → OnClickListener 인터페이스를 구현하는 익명 클래스를 만들었어
- onClick(View v) → 이 메서드를 오버라이드해서 버튼을 클릭했을 대 실행할 동작을 정의한 거야.
코틀린에서 람다를 사용
button.setOnClickListener { view -> ... }- 코틀린에서는 무명 클래스 인스턴스 대신 람다를 넘길 수 있다.
- OnClickListener를 구현하기 위해 사용한 람다에는 view라는 파라미터가 있다.
- view의 타입은 View, 이는 onClick 메소드의 인자 타입과 같다.
람다의 파라미터는 메소드의 파라미터와 대응한다.
public interface OnClickListener {
void onClick(View v); -> { view -> ... }
}
함수형 인터페이스(Fuctional Interface)?
“단 하나의 추상 메서드만 가지는 인터페이스”를 뜻하고 SAM(Single Abstract Method) 인터페이스라고도 부른다.
- 자바에서 많이 쓰이는 대표적인 함수형 인터페이스들
- Runnable → run() 메서드 한 개만 있음.
- Callable<T> → call() 메서드 한 개만 있음.
- ActionListener → actionPerformed(ActionEvent e) 메서드 한 개만 있음.
// Runnable 인터페이스 (자바)
Runnable r = () -> System.out.println("쓰레드 실행됨!");
new Thread(r).start();// Runnable을 코틀린에서 람다로 사용
Thread { println("쓰레드 실행됨!") }.start()
자바 8 이후 람다 표현식으로 대체 가능
button.setOnClickListener(v -> {
System.out.println("버튼이 클릭됨!");
});- 자바 8 이후 람다 표현식으로 대체 가능
- OnClickListener가 단일 추상 메서드만 가진 인터페이스이므로, 람다( () → {} )로 변환 가능
- v -> { System.out.println("버튼이 클릭됨!"); } → onClick(View v)의 구현 내용을 람다로 직접 전달
코틀린에서 더 간결하게 사용 가능
button.setOnClickListener { view ->
println("버튼이 클릭됨!")
}- 코틀린은 자바의 함수형 인터페이스를 인자로 받는 메서드를 호출할 때 람다를 사용할 수 있도록 함
- 즉, setOnClickListener를 람다만으로 표현할 수 있게 해줌.
- { view -> println("버튼이 클릭됨!") } → onClick(View v)를 자동으로 람다로 변환해서 사용 가능!
“코틀린에는 함수 타입이 존재하며, 함수형 인터페이스 대신 함수 타입을 사용해야 한다"
- 자바와 코틀린의 함수 처리 방식이 다르다.
- 코틀린에는 함수 타입(Function Type) 이 존재하기 때문에, 함수형 인터페이스를 사용할 필요가 없다.
- 코틀린은 함수를 값처럼 다룰 수 있음 → 함수 타입(Function Type) 사용 가능
- 그래서 자바처럼 함수형 인터페이스를 만들 필요가 없다!
- 람다를 함수의 인자로 직접 전달할 수 있다.
- 자바에서는 왜 함수형 인터페이스가 필요할까?
- 자바에는 "함수 자체를 전달하는 기능" 이 없어.
- 그래서 람다 표현식을 사용하려면 반드시 함수형 인터페이스가 필요해!
자바에서 함수형 인터페이스 사용 예제
// 함수형 인터페이스 정의 (SAM 인터페이스)
interface MyFunction {
void run();
}
public class Main {
public static void main(String[] args) {
MyFunction f = () -> System.out.println("Hello, World!");
f.run(); // 출력: Hello, World!
}
}- 자바에서는 람다를 사용하려면 반드시 함수형 인터페이스(SAM)를 만들어야 함.
- MyFunction 인터페이스 없이 ()->{} 를 사용할 수 없음!
코틀린에서는 함수 타입이 존재한다!
- 코틀린은 "함수 자체를 값으로 사용할 수 있는 기능"이 있음!
- 즉, 코틀린에서는 함수형 인터페이스 없이도 람다를 직접 함수의 인자로 전달 가능!
코틀린에서 함수 타입 사용 예제
// 함수 타입을 매개변수로 받는 함수
fun execute(action: () -> Unit) {
action() // 전달받은 함수를 실행
}
fun main() {
execute { println("Hello, World!") }
}- () -> Unit → 함수를 인자로 받는 함수 타입 선언
- execute { println("Hello, World!") } → 함수형 인터페이스 없이 람다 전달 가능!
코틀린은 자바 함수형 인터페이스를 자동 변환해주지 않는다
자바에서는 함수형 인터페이스가 필수적이지만, 코틀린은 함수 타입을 직접 사용할 수 있기 때문에 자동 변환을 제공하지 않음.
예제: 자바 인터페이스를 코틀린에서 사용하면?
@FunctionalInterface
interface ClickListener {
void onClick();
}
public class Button {
public void setOnClickListener(ClickListener listener) {
listener.onClick();
}
}val button = Button()
// 자바 함수형 인터페이스에는 람다 사용 가능 (SAM 변환 지원)
button.setOnClickListener { println("버튼 클릭!") }- 코틀린에서는 자바의 함수형 인터페이스(SAM)를 자동으로 람다로 변환해줌
- 하지만, 코틀린에서 정의한 함수 타입은 자바의 함수형 인터페이스로 자동 변환되지 않는다!
5.4.1 자바 메소드에 람다를 인자로 연결
함수형 인터페이스를 인자로 원하는 자바 메소드에 코틀린 람다를 전달할 수 있다. 코틀린에서는 자바의 함수형 인터페이스(SAM 인터페이스)를 사용하는 메소드에 람다를 직접 전달할 수 있다. 이 과정에서 컴파일러가 자동으로 무명 클래스를 생성하고 인스턴스를 만들어준다.
자바에서 함수형 인터페이스를 인자로 받는 메서드
자바에서는 람다 표현식을 직접 사용할 수 없기 때문에 반드시 함수형 인터페이스(SAM)을 구현한 객체를 인자로 전달해야 한다.
자바에서 Runnable을 인자로 받는 메서드
void postponeComputation(int delay, Runnable computation);- Runnable은 SAM 인터페이스 (단 하나의 추상 메서드만 있음)
- computation 매개변수는 Runnable 타입이므로, Runnable을 구현한 객체를 넘겨야 함.
자바에서 Runnable을 명시적으로 넘기는 방식
postponeComputation(1000, new Runnable() {
@Override
public void run() {
System.out.println(42);
}
});- 자바에서는 보통 익명 클래스를 사용해서 Runnable을 넘겨야 해.
- new Runnable() { ... } → 익명 클래스로 Runnable을 구현
- run() 메서드 내부에서 실제로 실행될 코드(42 출력)를 작성
코틀린에서 람다로 변환하기
postponeComputation(1000) { println(42) }- 코틀린에서는 자바의 함수형 인터페이스를 직접 람다로 전달 가능!
- { println(42) } → 람다를 바로 인자로 전달!
- Runnable이 필요한 곳에 컴파일러가 자동으로 Runnable을 구현한 객체로 변환해줌.
- 자동으로 Runnable 인스턴스(Runnable을 구현한 무명 클래스의 인스턴스)로 변환해줌
코틀린에서 무명 객체를 명시적으로 사용할 수 있다.
postponeComputation(1000, object : Runnable {
override fun run() {
println(42)
}
})- 코틀린에서도 익명 객체를 직접 만들어서 사용할 수 있어.
- object : Runnable { ... } → 명시적으로 무명 객체 생성
- 자바에서 익명 클래스를 사용하는 것과 같은 방식이지만, 코틀린에서는 필요하지 않다!
- 람다는 컴파일러가 자동 변환하여 재사용할 수 있다. (인스턴스 단 하나만 만들어짐)
- 즉, 람다에 대응하는 무명 객체를 메소드를 호출할 때마다 반복 사용한다.
- 무명 객체는 메서드를 호출할 때마다 새로운 인스턴스가 생성된다.
차이점 예제
val runnable = Runnable { println(42) } // 단 하나의 인스턴스만 존재
fun handleComputation() {
postponeComputation(1000, runnable) // 같은 객체를 계속 사용
}- Runnable 객체를 변수에 저장하면 프로그램 전체에서 같은 인스턴스를 사용!
반면, 람다가 주변 변수를 포획하면 매번 새로운 인스턴스를 생성해!
fun handleComputation(id: String) { //람다 안에서 "id" 변수를 포획한다.
postponeComputation(1000) { println(id) } // 호출할 때마다 새로운 객체 생성
}- 변수를 포획한다?
- 코틀린에서는 람다 내부에서 외부 변수(주변 변수)를 사용할 수 있다. 이때 람다는 외부 변수를 직접 참조하는 것이 아니라, 그 변수를 포함하는 새로운 객체를 생성하는데, 이를 "변수를 포획(Capture)한다"라고 한다!
- { println(id) } → 람다가 id 변수를 포획
- 호출할 때마다 새로운 Runnable 인스턴스가 만들어짐!
람다를 무명 클래스(Anonymous Class)로 변환하는 과정과 최적화 방법을 다루고 있어.
람다는 무명 클래스로 변환된다 → 코틀린에서 람다는 사실상 익명 함수야.
즉, 컴파일될 때 무명 클래스로 변환되어 객체가 생성된다.
fun handleComputation(id: String) {
postponeComputation(1000) { println(id) }
}- { println(id) } → 람다 사용
- 컴파일러는 이 람다를 Runnable을 구현한 익명 클래스로 변환해.
람다를 무명 클래스로 변환하는 방식
- 컴파일러는 람다를 포함하는 무명 클래스를 생성하고,
- 해당 클래스의 인스턴스를 만들어서 메서드에 넘긴다.
변환된 코드 (컴파일 후 예상되는 코드)
class HandleComputationS1(val id: String) : Runnable {
override fun run() {
println(id)
}
}
fun handleComputation(id: String) {
postponeComputation(1000, HandleComputationS1(id))
}- HandleComputationS1 → Runnable을 구현한 새로운 클래스가 자동 생성됨.
- 람다 내부에서 외부 변수(id)를 사용하면 필드로 저장해야 함.
- 따라서 호출할 때마다 새로운 객체가 생성됨!
람다가 외부 변수를 포획하면?
- 람다가 외부 변수를 사용(포획) 하면,
- 컴파일러는 해당 변수를 저장할 필드를 가진 새로운 무명 클래스를 생성해.
람다가 외부 변수를 포획하는 경우
fun handleComputation(id: String) {
postponeComputation(1000) { println(id) } // id를 포획
}- id 변수를 사용했기 때문에 id를 저장할 필드가 있는 클래스가 생성됨.
- 그리고 handleComputation("Hello") 를 호출할 때마다 새로운 객체가 생성됨.
최적화: 코틀린의 inline 함수
- 코틀린에서는 inline 키워드를 사용하면 무명 클래스를 만들지 않고 최적화할 수 있어!
- 즉, 무명 클래스를 생성하는 대신, 함수 자체를 복사해서 사용함.
inline 최적화 적용
inline fun handleComputation(id: String) {
postponeComputation(1000) { println(id) } // id를 포획하지만 무명 클래스 생성 없음
}- inline 키워드를 사용하면 컴파일러가 람다 자체를 코드에 삽입!
- 따라서 무명 클래스가 생성되지 않음 → 성능 최적화 가능!
Inline의 장점
- 무명 클래스 인스턴스를 생성하지 않음 → 메모리 절약
- 메서드 호출 없이 코드 자체를 삽입 → 함수 호출 오버헤드 감소
- 반복적으로 호출되는 경우 성능 개선 가능!
정리
- 코틀린 람다는 기본적으로 무명 클래스로 변환됨.
- 람다가 외부 변수를 포획하면, 변수를 저장할 필드가 있는 새로운 객체가 생성됨.
- handleComputation("Hello")를 호출하면 새로운 Runnable 객체가 생성됨.
- inline 키워드를 사용하면 무명 클래스를 생성하지 않고 최적화 가능
5.4.2 SAM 생성자: 람다를 함수형 인터페이스로 명시적으로 변경
- SAM(Single Abstract Method) 인터페이스: 단 하나의 추상 메서드만 가진 인터페이스
- 자바에서는 람다를 사용하려면 함수형 인터페이스가 필요, 코틀린에서는 람다를 직접 함수로 사용
컴파일러가 자동으로 람다를 함수형 인터페이스 무명 클래스로 변환하지 못하는 경우에는 직접 변환을 도와주는 SAM 생성자를 사용할 수 있다.
SAM 생성자를 사용해 값 반환하기
fun createAllDoneRunnable(): Runnable {
return Runnable { println("All done!") }
}
fun main() {
createAllDoneRunnable().run() // 출력: All done!
}- SAM 생성자의 이름은 사용하려는 함수형 인터페이스의 이름과 같다.
- SAM 생성자는 그 함수형 인터페이스의 유일한 추상 메소드의 본문에 사용할 람다만을 인자로 받아서 함수형 인터페이스를 구현하는 클래스의 인스턴스를 반환한다.
- Runnable { println("All done!") } → SAM 생성자를 사용해 람다를 Runnable 객체로 변환
- createAllDoneRunnable() 함수는 Runnable을 반환하므로, run()을 호출하면 "All done!"이 출력됨.
- 람다는 익명 함수라서 직접 반환할 수 없음.
- SAM 생성자를 사용하면, 람다를 함수형 인터페이스로 변환하여 반환할 수 있음.
- SAM 생성자를 사용하는 이유 : 코틀린에서 자바 코드와의 상호운용성 때문일까?
SAM 생성자는 코틀린에서 자바의 함수형 인터페이스(SAM)를 사용할 때 주로 필요하지만, 코틀린 자체적인 이유로도 필요할 수 있다.
1. SAM 생성자가 필요한 이유
코틀린에서는 함수를 값처럼 다룰 수 있기 때문에 람다를 직접 반환할 수 있을 것 같지만,
자바의 함수형 인터페이스를 반환해야 하는 경우에는 변환 과정이 필요하다!
자바에서 함수형 인터페이스를 사용하는 경우
@FunctionalInterface
interface Runnable {
void run();
}
public class JavaInterop {
public static Runnable getRunnable() {
return () -> System.out.println("Hello from Java!");
}
}- Runnable은 자바의 함수형 인터페이스 (SAM)
- getRunnable() → 람다를 반환하지만, Runnable 타입으로 변환해야 함!
2. 코틀린에서는 람다를 직접 반환할 수 없을까?
코틀린에서는 람다 자체를 직접 반환하는 것은 불가능하다! 코틀린에서 람다는
일반적인 객체가 아니라 "익명 함수(Anonymous Function)"로 처리되기 때문이다.
잘못된 코드 (컴파일 오류 발생)
fun createAllDoneRunnable(): Runnable {
return { println("All done!") } // 오류 발생
}- return { println("All done!") } → 람다는 Runnable이 아니므로 반환 불가능하다
- 코틀린에서는 람다를 반환할 수 없기 때문에, 반드시 변환 과정이 필요함.
⇒ 그래서 SAM 생성자를 사용하면 해결할 수 있다!
3. SAM 생성자를 사용하면 해결 가능!
fun createAllDoneRunnable(): Runnable {
return Runnable { println("All done!") } // 올바른 코드
}- Runnable { println("All done!") } → SAM 생성자가 람다를 Runnable로 변환해줌.
- 이렇게 하면 코틀린에서 람다를 자바의 함수형 인터페이스로 변환할 수 있음!
4. SAM 생성자가 꼭 자바 코드와 관련이 있을까?
SAM 생성자는 주로 자바 함수형 인터페이스를 사용할 때 필요하지만,
코틀린에서도 람다를 특정 인터페이스 타입으로 변환해야 할 때 유용해.
코틀린에서 자체적으로 SAM 생성자가 필요할 수도 있다!
interface MyFunctionalInterface {
fun execute()
}
fun getFunction(): MyFunctionalInterface {
return MyFunctionalInterface { println("Executing function!") } // ✅ 가능
}
fun main() {
getFunction().execute() // 출력: Executing function!
}- MyFunctionalInterface { println("Executing function!") } → SAM 생성자를 사용해 람다를 인터페이스 구현체로 변환!
- 이처럼 자바가 아니라도, 함수형 인터페이스를 반환하려면 SAM 생성자가 필요할 수 있음.
5. 결론
- SAM 생성자는 코틀린에서 자바의 함수형 인터페이스(SAM)를 사용할 때 필요!
- Runnable, Callable, OnClickListener 같은 인터페이스를 사용할 때 자주 활용됨.
- 코틀린 자체적으로도 특정 함수형 인터페이스를 반환해야 할 때 유용!
- 자바가 아니더라도, 람다를 특정 인터페이스 타입으로 변환할 필요가 있을 때 SAM 생성자가 필요할 수 있음.
- 람다는 인터페이스가 아니므로 직접 반환할 수 없음.
- return { ... } → 오류 발생
- return Runnable { ... } → 올바른 방법 (SAM 생성자 사용)
SAM 생성자로 리스너 인스턴스 재사용하기
val listener = OnClickListener { view ->
val text = when (view.id) {
R.id.button1 -> "First button"
R.id.button2 -> "Second button"
else -> "Unknown button"
}
toast(text)
}
// 같은 리스너를 여러 버튼에 적용 가능!
button1.setOnClickListener(listener)
button2.setOnClickListener(listener)- 버튼 클릭 리스너 같은 이벤트 리스너를 여러 개의 UI 요소에서 공유해야 할 때,
- SAM 생성자를 사용하면 하나의 리스너 인스턴스를 재사용할 수 있어.
- OnClickListener { view -> ... } → SAM 생성자로 OnClickListener 객체 생성
- listener 변수에 저장하여 여러 버튼에서 재사용 가능!
- button1과 button2에 동일한 리스너를 설정할 수 있음.
SAM 생성자의 장점
- 여러 UI 요소에서 같은 리스너를 재사용 가능 → 메모리 절약 & 코드 중복 감소
- 컴파일러가 자동 변환하지 못하는 경우 명시적으로 변환 가능
리스너 등록/해제
val listener = object : OnClickListener {
override fun onClick(view: View) {
println("Button clicked!")
}
}
button.setOnClickListener(listener)
button.setOnClickListener(null) // 리스너 해제- 람다에는 무명 객체와 달리 this가 없기 때문에, 리스너 등록/해제가 어려울 수 있다!
- 이럴 때는 무명 객체를 사용해야 한다!
- object : OnClickListener { ... } → 무명 객체를 사용해서 리스너를 등록
- button.setOnClickListener(null) → 등록한 리스너를 해제 가능
이 방식이 필요한 이유
- 람다에는 this가 없어서, 리스너를 해제하려면 객체가 필요함.
- 무명 객체를 사용하면, 같은 객체를 참조하여 등록/해제 가능.
컴파일러가 자동 변환해 줄 수 없는 경우에는 명시적으로 SAM 생성자를 사용해야 한다.
- 예를 들어
- 람다를 반환해야 할 때 (return 키워드 사용)
- 여러 UI 요소에서 같은 리스너를 공유할 때
- 람다에 this가 없어서 특정 객체를 참조해야 할 때
팀원5 part (5.5 수신 객체 지정 람다: with와 apply)
- with와 apply는 코틀린 표준 라이브러리 → 매우 편리
- 이번 절에서는 자바의 람다에는 없는 코틀린 람다의 독특한 기능을 설명 → 수신 객체를 명시하지 않고 람다의 본문 안에서 다른 객체의 메소드를 호출할 수 있게 하는 것
- 그런 람다를 수신 객체 지정 람다(lambda with receiver)라고 부름
5.5.1 with 함수
- 어떤 객체의 이름을 반복하지 않고도 그 객체에 대해 다양한 연산을 수행할 수 있다면 좋을 것 → with라는 라이브러리 함수
fun alphabet (): String {
val result = StringBuilder()
for (letter int 'A'..'Z') {
result.append(letter)
}
result.append("\nNow I know the alphabet!")
return result.toString()
}
>>> println(alphabet())
ABCDEFGHIJKLMNOPQRSTUVWXYZ
Now I know the alphabet!- 이 예제에서 result에 대해 여러 메소드를 호출하면서 매번 result를 반복 사용 → result를 더 자주 반복해야 했다면 좀 그럼
fun alphabet(): String {
val stringBuilder = StringBuilder()
return with(stringBuilder) { // 메소드를 호출하려는 수신 객체 지정
for (letter in 'A'..'Z') {
this.append(letter) // "this"를 명시해서 앞에서 지정한 수신 객체 호출
}
append("\nNow I know the alphabet!") // "this"를 생략하고 메소드 호출
this.toString() // 람다에서 값을 반환
}
}- with문은 파라미터가 2개 있는 함수 → 첫 번째 파라미터는 stringBuilder이고, 두 번째 파라미터는 람다
- stringBuilder의 메소드를 this.append(letter)처럼 this 참조를 통해 접근하거나 append(”\nNow…”)처럼 바로 호출할 수 있음
inline fun <T, R> with(receiver: T, block: T.() -> R): R- with 함수는 첫 번째 인자로 받은 객체를 두 번째 인자로 받은 람다의 수신 객체로 만듬
- 인자로 받은 람다 본문에서는 this를 사용해 그 수신 객체에 접근
- 일반적인 this와 마찬가지로 this와 점(.)을 사용하지 않고 프로퍼티나 메소드 이름만 사용해도 수신 객체의 멤버에 접근할 수 있음
- 앞의 alphabet 함수를 더 리팩토링해서 불필요한 stringBuilder 변수를 없앨 수도 있음
fun alphabet () = with(StringBuilder()) {
for (letter in 'A'..'Z') {
append(letter)
}
append("\nNow I know the alphabet!")
toString()
}- 불필요한 stringBuilder 변수를 없애면 alphabet 함수가 식의 결과를 바로 반환하게 됨 → 식을 본문으로 하는 함수로 표현 가능
- StringBuilder의 인스턴스를 만들고 즉시 with에게 인자로 넘기고, 람다 안에서 this를 사용해 그 인스턴스를 참조
val person = Person("Alice", 25)
val description = with(person) {
println("이름: $name")
"나이: ${age}세"
}
// 콘솔에 이름이 출력되고, descripption엔 나이가 저장됨class OuterClass {
fun toString(): String {
return "OuterClass의 toString"
}
fun alphabet(): String {
return with(StringBuilder()) {
append("ABC")
// 만약 여기서 OuterClass의 toString을 부르고 싶다면?
this@OuterClass.toString()
//this.toString() 만 하면 StringBuilder.toString이 호출됨
}
}
}- with가 반환하는 값은 람다 코드를 실행한 결과며, 그 결과는 람다 식의 본문에 있는 마지막 식의 값
- 하지만 때로는 람다의 결과 대신 수신 객체가 필요한 경우도 있음
5.5.2 apply 함수
- apply 함수는 with와 거의 같음 → 유일한 차이는 apply는 항상 자신에게 전달된 객체(수신객체)를 반환한다는 점
fun alphabet () = StringBuilder().apply{
for (letter in 'A'..'Z') {
append(letter)
}
append("\nNow I know the alphabet!")
}.toString()- apply는 확장 함수로 정의돼 있음 → apply의 수신 객체가 전달받은 람다의 수신 객체가 됨
- 이 함수에서 apply를 실행한 결과는 StringBuilder 객체 → 그 객체의 toString을 호출해서 String 객체를 얻을 수 있음
inline fun <T> T.apply(block: T.() -> Unit): T- with와 같이 apply도 this 생략 가능
val person = Person().apply {
name = "Bob"
age = 30
}
// person 객체가 그대로 반환
// val person = Person("Bob", 30)과 무슨 차이?
// 생성자에 파라미터가 많지 않고 단순히 초기값을 넣는 경우엔 주 생성자로 직접 할당하는 것이 더 간결하지만, 생성 로직이 복잡하거나, 프로퍼티를 여러 단계에 걸쳐 초기화해야 경우엔 apply를 사용하면 가독성이 높아짐
// 예: 여러 프로퍼티를 단계별로 설정하거나, 추가적인 메소드를 호출해야 할 때- apply 함수는 객체의 인스턴스를 만들면서 즉시 프로퍼티 중 일부를 초기화 하는 경우 유용
- 자바에서는 보통 별도의 Builder 객체가 이런 역할을 담당
- 코틀린에서는 어떤 클래스가 정의돼 있는 라이브러리의 특별한 지원 없이도 그 클래스 인스턴스에 대해 apply를 활용할 수 있음
fun createViewWithCustomAttributes(context: Context) =
TextView(context).apply {
text = "Sample Text"
textSize = 20.0
setPadding(10, 0, 0, 0)
}- apply 함수를 사용하면 함수의 본문에 간결한 식을 사용할 수 있음
- 새로운 TextView 인스턴스를 만들고 즉시 그 인스턴스를 apply에 넘김
- apply에 전달된 람다 안에서는 TextView가 수신 객체가 됨 → 원하는 대로 TextView의 메소드를 호출하거나 프로퍼티를 설정할 수 있음
- 람다를 실행하고 나면 apply는 람다에 의해 초기화된 TextView 인스턴스를 반환하고 그 인스턴스는 createViewWithCustomAttributes 함수의 결과가 됨
fun alphabet () = buildString {
for (letter in 'A' .. 'Z') {
append(letter)
}
append("\nNow I know the alphabet!")
}- with와 apply는 수신 객체 지정 람다를 사용하는 일반적인 예제 중 하나 → 더 구체적인 함수를 비슷한 패턴으로 활용 가능
- 표준 라이브러리의 buildString 함수를 사용하면 alphabet 함수를 더 단순화할 수 있음
- buildString은 앞에서 살펴 본 alphabet 코드에서 StringBuilder 객체를 만드는 일과 toString을 호출해주는 일을 알아서 해줌
- buildString의 인자는 수신 객체 지정 람다며, 수신 객체는 항상 StringBuilder가 됨 → StringBuilder를 활용해 String을 만드는 경우 사용할 수 있는 우아한 해법
도서 링크 바로가기
https://product.kyobobook.co.kr/detail/S000001804588
Kotlin in Action | 드미트리 제메로프 - 교보문고
Kotlin in Action | 코틀린이 안드로이드 공식 언어가 되면서 관심이 커졌다. 이 책은 코틀린 언어를 개발한 젯브레인의 코틀린 컴파일러 개발자들이 직접 쓴 일종의 공식 서적이라 할 수 있다. 코틀
product.kyobobook.co.kr
'Programming Language > Kotlin' 카테고리의 다른 글
| [Kotlin In Action] 7장. 연산자 오버로딩과 기타 관례 정리 feat. 내가 정리한 부분만 (0) | 2025.04.03 |
|---|---|
| [Kotlin In Action] 6장. 코틀린 타입 시스템 정리 feat. 내가 정리한 부분만 (0) | 2025.04.03 |
| [Kotlin In Action] 4장. 클래스 , 객체 , 인터페이스 정리 (0) | 2025.03.21 |
| [Kotlin In Action] 3장. 함수 정의와 호출 정리 (0) | 2025.03.20 |
| [Kotlin In Action] 2장. 코틀린 기초 스터디 정리 (0) | 2025.03.01 |